PhysMani: Physics-principled 3D World Model for Dynamic Object Manipulation
Pith reviewed 2026-07-03 12:01 UTC · model grok-4.3
The pith
PhysMani couples a 3D Gaussian world model enforcing a divergence-free velocity field with a future-aware policy to improve dynamic object manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
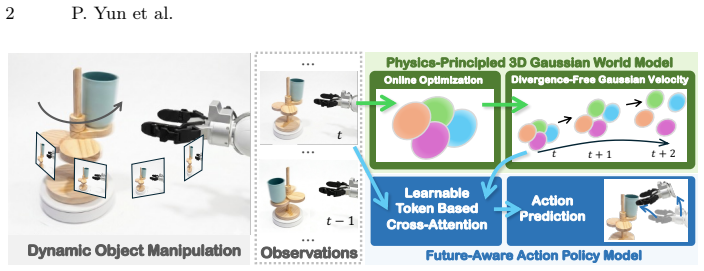
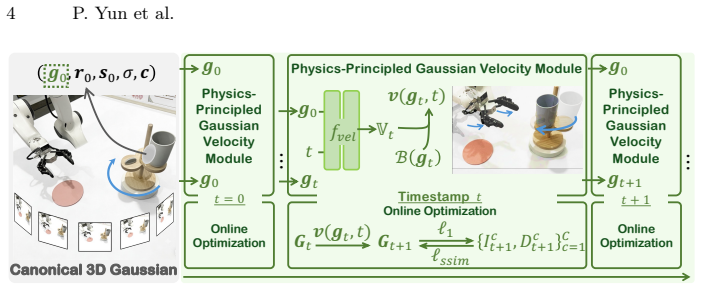
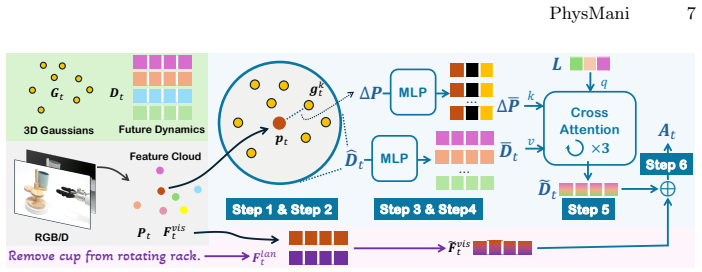
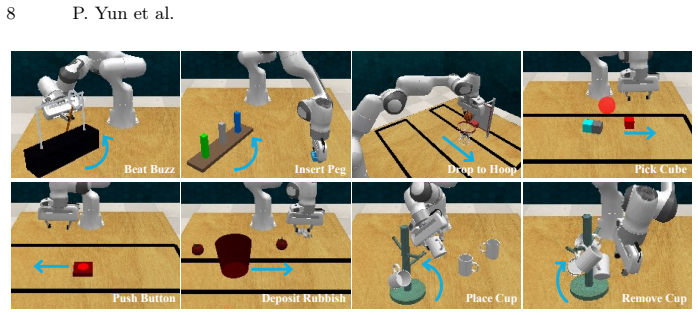
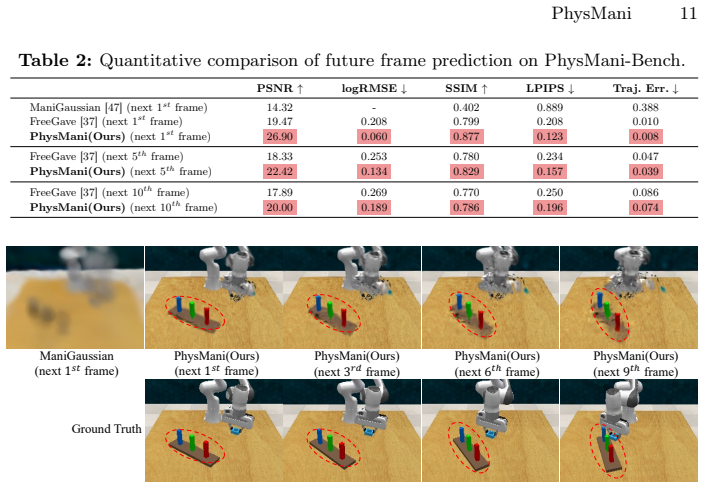
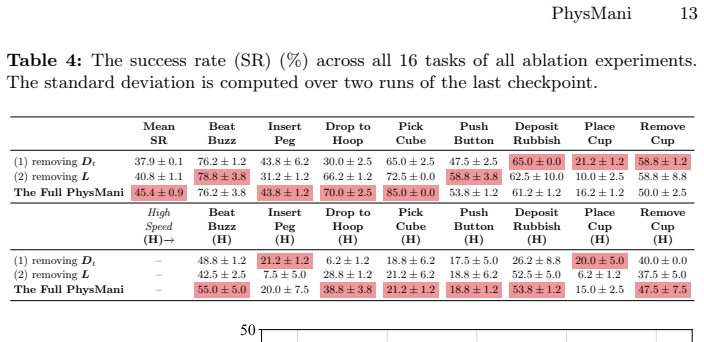
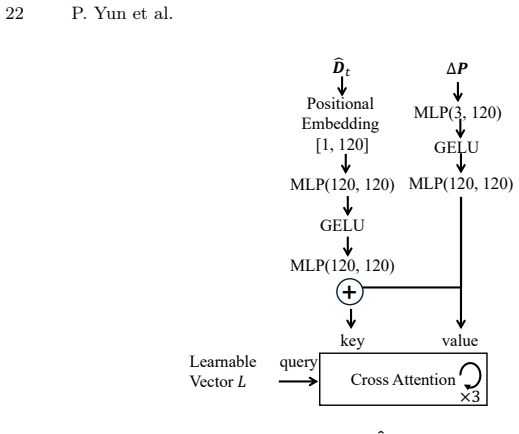
PhysMani couples a physics-principled 3D Gaussian world model with a future-aware action policy model. The world model learns a divergence-free Gaussian velocity field via online optimization for fast and physically grounded future dynamics prediction. The policy model integrates the predicted 3D scene future dynamics through a learnable token based cross-attention module. On the introduced PhysMani-Bench with 16 tasks, the framework achieves superior success rates over strong baselines in both simulation and real-world robot experiments.
What carries the argument
divergence-free Gaussian velocity field learned via online optimization inside a 3D Gaussian world model, which supplies physically consistent future dynamics to the policy via cross-attention
If this is right
- The world model supplies 3D scene futures that the policy can use directly for action selection in dynamic settings.
- Online optimization of the velocity field allows the system to adapt predictions without full retraining on new scenes.
- The same framework yields measurable gains on a 16-task benchmark in both simulated and physical robot settings.
- Cross-attention integration of predicted dynamics improves handling of unstructured environments over models lacking explicit physics constraints.
Where Pith is reading between the lines
- The divergence-free constraint might generalize to other fluid or rigid-body prediction tasks if the online solver remains stable at higher speeds.
- Real-world deployment could benefit from testing whether the Gaussian representation scales to cluttered scenes with partial observability.
- Combining the velocity field with additional constraints such as conservation of momentum could further reduce prediction drift over longer horizons.
Load-bearing premise
Enforcing a divergence-free condition on the learned Gaussian velocity field through online optimization produces forecasts accurate and meaningful enough to improve policy decisions with fast-moving targets.
What would settle it
A direct comparison on PhysMani-Bench tasks with rapid motion where the full PhysMani pipeline shows no statistically significant gain in success rate over the policy model alone or over prior world-model baselines.
Figures





read the original abstract
Manipulating fast and dynamically moving targets in unstructured 3D environments remains challenging for embodied AI. Existing visual-language-action models and world models struggle with accurate 3D geometry and physically meaningful forecasting. We propose PhysMani, a framework that couples a physics-principled 3D Gaussian world model with a future-aware action policy model. The world model learns a divergence-free Gaussian velocity field via online optimization for fast and physically grounded future dynamics prediction. The policy model integrates the predicted 3D scene future dynamics through a learnable token based cross-attention module. We introduce PhysMani-Bench, a dynamic manipulation benchmark with 16 tasks, and demonstrate a superior success rate over strong baselines in both simulation and real-world robot experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce PhysMani, which couples a physics-principled 3D Gaussian world model learning a divergence-free Gaussian velocity field via online optimization for future dynamics prediction with a future-aware action policy model using cross-attention. It introduces PhysMani-Bench with 16 tasks and demonstrates superior success rates over strong baselines in simulation and real-world robot experiments.
Significance. If the result holds and the physics constraint is shown to be responsible, it could advance the field by providing physically grounded world models for dynamic manipulation tasks. However, the current presentation does not allow assessment of whether the divergence-free condition improves forecasts for rigid-body dynamics under contacts and gravity.
major comments (2)
- [Abstract] The abstract asserts superior success rates but supplies no metrics, baseline descriptions, error analysis, or validation that the divergence-free constraint actually drives the gains rather than other modeling choices.
- The central claim requires that the learned velocity field (enforced ∇·v=0) produces forecasts accurate enough to improve the cross-attention policy over baselines. This condition is appropriate for incompressible flow but is only an approximation for the rigid, colliding, and gravity-driven objects in PhysMani-Bench; without specific results showing reduced prediction error attributable to this constraint, the success-rate gains cannot be attributed to the physics principle.
minor comments (1)
- The manuscript would benefit from including quantitative tables with success rates, prediction errors, and ablation studies on the divergence-free constraint.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the concerns regarding the abstract and the attribution of gains to the divergence-free constraint below, and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts superior success rates but supplies no metrics, baseline descriptions, error analysis, or validation that the divergence-free constraint actually drives the gains rather than other modeling choices.
Authors: We agree that the abstract would be strengthened by including quantitative metrics and baseline details. In the revised version, we will update the abstract to report specific success rates on PhysMani-Bench (e.g., average improvement over baselines), briefly describe the 16 tasks, and note the role of the physics constraint. We will also add a short reference to the ablation results validating the constraint's contribution. revision: yes
-
Referee: The central claim requires that the learned velocity field (enforced ∇·v=0) produces forecasts accurate enough to improve the cross-attention policy over baselines. This condition is appropriate for incompressible flow but is only an approximation for the rigid, colliding, and gravity-driven objects in PhysMani-Bench; without specific results showing reduced prediction error attributable to this constraint, the success-rate gains cannot be attributed to the physics principle.
Authors: We acknowledge that the divergence-free constraint is an approximation for rigid-body dynamics involving contacts and gravity, rather than a perfect model of incompressible flow. The manuscript presents the constraint as a useful inductive bias for stable velocity field learning in 3D Gaussians. To directly address attribution, we will add ablation experiments in the revision that compare prediction error (e.g., mean squared velocity error and divergence metrics) and downstream success rates with and without the ∇·v=0 enforcement. This will provide evidence on whether the constraint reduces forecast error and drives policy improvements. We maintain that the online optimization with this constraint yields more physically grounded predictions than unconstrained alternatives in our tasks. revision: yes
Circularity Check
No significant circularity in derivation chain.
full rationale
The abstract and provided text describe a new coupling of a 3D Gaussian world model (with divergence-free velocity field learned via online optimization) to a cross-attention policy. No equations, self-citations, or steps are exhibited that reduce the claimed 'physically grounded future dynamics prediction' to a fitted input or prior result by construction. The optimization and policy integration are presented as independent methodological contributions rather than tautological renamings or self-referential definitions. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: GPT-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Cosmos World Foundation Model Platform for Physical AI
Agarwal, N., Ali, A., Bala, M., Balaji, Y., Barker, E., Cai, T., Chattopadhyay, P., Chen, Y., Cui, Y., Ding, Y., et al.: Cosmos world foundation model platform for physical AI. arXiv preprint arXiv:2501.03575 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
In: IEEE/RSJ International Conference on Intelligent Robots and Systems
Akinola, I., Xu, J., Song, S., Allen, P.K.: Dynamic grasping with reachability and motion awareness. In: IEEE/RSJ International Conference on Intelligent Robots and Systems. pp. 9422–9429 (2021)
2021
-
[4]
World Simulation with Video Foundation Models for Physical AI
Ali, A., Bai, J., Bala, M., Balaji, Y., Blakeman, A., Cai, T., Cao, J., Cao, T., Cha, E., Chao, Y.W., et al.: World simulation with video foundation models for physical AI. arXiv preprint arXiv:2511.00062 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Assran, M., Bardes, A., Fan, D., Garrido, Q., Howes, R., Muckley, M., Rizvi, A., Roberts, C., Sinha, K., Zholus, A., et al.: V-JEPA 2: Self-supervised video models enable understanding, prediction and planning. arXiv preprint arXiv:2506.09985 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
In: SIGGRAPH Asia 2024 Conference Papers
Bar-Tal, O., Chefer, H., Tov, O., Herrmann, C., Paiss, R., Zada, S., Ephrat, A., Hur, J., Liu, G., Raj, A., et al.: Lumiere: A space-time diffusion model for video generation. In: SIGGRAPH Asia 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[7]
In: International Conference on Learning Representa- tions
Barcellona, L., Zadaianchuk, A., Allegro, D., Papa, S., Ghidoni, S., Gavves, E.: Dream to manipulate: Compositional world models empowering robot imitation learning with imagination. In: International Conference on Learning Representa- tions. vol. 2025, pp. 56729–56763 (2025)
2025
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Bi, H., Tan, H., Xie, S., Wang, Z., Huang, S., Liu, H., Zhao, R., Feng, Y., Xiang, C., Rong, Y., et al.: Motus: A unified latent action world model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 35101–35113 (2026)
2026
-
[9]
In: Conference on Robot Learning (2025)
Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M.R., Finn, C., Fusai, N., Galliker, M.Y., et al.: pi0.5: a vision-language-action model with open-world generalization. In: Conference on Robot Learning (2025)
2025
-
[10]
In: Proceedings of Robotics: Science and Systems
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M.R., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., Jakubczak, S., Jones, T., Ke, L., Levine, S., Li-Bell, A., Mothukuri, M., Nair, S., Pertsch, K., Shi, L.X., Smith, L., Tanner, J., Vuong, Q., Walling, A., Wang, H., Zhilinsky, U.: pi0: A Vision-Language-Action Flow Model for General Robot Con...
2025
-
[11]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023) PhysMani 17
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
In: International Conference on Machine Learning (2024)
Bruce, J., Dennis, M.D., Edwards, A., Parker-Holder, J., Shi, Y., Hughes, E., Lai, M., Mavalankar, A., Steigerwald, R., Apps, C., et al.: Genie: Generative interactive environments. In: International Conference on Machine Learning (2024)
2024
-
[13]
arXiv preprint arXiv:2601.00051 (2026)
Chen, Y., Liang, Y., Wang, J., Chen, T., Cheng, J., Gu, Z., Huang, Y., Jiang, Z., Li, W., Li, T., et al.: TeleWorld: Towards dynamic multimodal synthesis with a 4d world model. arXiv preprint arXiv:2601.00051 (2026)
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Christen, S., Yang, W., Pérez-D’Arpino, C., Hilliges, O., Fox, D., Chao, Y.W.: Learning human-to-robot handovers from point clouds. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9654– 9664 (2023)
2023
-
[15]
Coumans, E., Bai, Y.: PyBullet, a Python module for physics simulation for games, robotics and machine learning.http://pybullet.org(2016–2021), last accessed 28 Jun 2026
2016
-
[16]
In: IEEE International Conference on Robotics and Automation
D’Ambrosio, D.B., Abeyruwan, S., Graesser, L., Iscen, A., Amor, H.B., Bewley, A., Reed, B.J., Reymann, K., Takayama, L., Tassa, Y., et al.: Achieving human level competitive robot table tennis. In: IEEE International Conference on Robotics and Automation. pp. 74–82 (2025)
2025
-
[17]
ACM Computing Surveys58(3), 1–38 (2025)
Ding, J., Zhang, Y., Shang, Y., Zhang, Y., Zong, Z., Feng, J., Yuan, Y., Su, H., Li, N., Sukiennik, N., et al.: Understanding world or predicting future? a compre- hensive survey of world models. ACM Computing Surveys58(3), 1–38 (2025)
2025
-
[18]
arXiv preprint arXiv:2507.17141 (2025)
Gao, G., Wang, J., Zuo, J., Jiang, J., Zhang, J., Zeng, X., Zhu, Y., Ma, L., Chen, K., Sheng, M., et al.: Towards human-level intelligence via human-like whole-body manipulation. arXiv preprint arXiv:2507.17141 (2025)
-
[19]
In: Conference on Robot Learn- ing (2023)
Gervet, T., Xian, Z., Gkanatsios, N., Fragkiadaki, K.: Act3D: 3D feature field transformers for multi-task robotic manipulation. In: Conference on Robot Learn- ing (2023)
2023
-
[20]
arXiv preprint arXiv:2508.11002 (2025)
Gkanatsios, N., Xu, J., Bronars, M., Mousavian, A., Ke, T.W., Fragkiadaki, K.: 3D FlowMatch Actor: Unified 3D policy for single-and dual-arm manipulation. arXiv preprint arXiv:2508.11002 (2025)
-
[21]
In: Conference on Robot Learning
Goyal, A., Xu, J., Guo, Y., Blukis, V., Chao, Y.W., Fox, D.: RVT: Robotic view transformer for 3D object manipulation. In: Conference on Robot Learning. pp. 694–710 (2023)
2023
-
[22]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Let- man,A.,Mathur,A.,Schelten,A.,Vaughan,A.,etal.:TheLlama3herdofmodels. arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Ha, D., Schmidhuber, J.: World models. arXiv preprint arXiv:1803.101222(3), 440 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
Nature640(8059), 647–653 (2025)
Hafner, D., Pasukonis, J., Ba, J., Lillicrap, T.: Mastering diverse control tasks through world models. Nature640(8059), 647–653 (2025)
2025
-
[25]
In: Advances in Neural Information Processing Systems
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: Advances in Neural Information Processing Systems. NIPS ’20, Curran Associates Inc., Red Hook, NY, USA (2020)
2020
-
[26]
In: International Con- ference on Learning Representations (2022)
Hu, E.J., yelong shen, Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language models. In: International Con- ference on Learning Representations (2022)
2022
-
[27]
IEEE Robotics and Automation Letters5(2), 3019–3026 (2020)
James, S., Ma, Z., Arrojo, D.R., Davison, A.J.: RLBench: The robot learning benchmark & learning environment. IEEE Robotics and Automation Letters5(2), 3019–3026 (2020)
2020
-
[28]
In: Proceedings 18 P
James, S., Wada, K., Laidlow, T., Davison, A.J.: Coarse-to-fine q-attention: Effi- cient learning for visual robotic manipulation via discretisation. In: Proceedings 18 P. Yun et al. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13739–13748 (2022)
2022
-
[29]
IEEE Access (2025)
Kawaharazuka, K., Oh, J., Yamada, J., Posner, I., Zhu, Y.: Vision-language-action models for robotics: A review towards real-world applications. IEEE Access (2025)
2025
-
[30]
In: Conference on Robot Learning (2024)
Ke, T.W., Gkanatsios, N., Fragkiadaki, K.: 3D Diffuser Actor: Policy diffusion with 3D scene representations. In: Conference on Robot Learning (2024)
2024
-
[31]
ACM Transactions on Graphics42(4) (Jul 2023)
Kerbl, B., Kopanas, G., Leimkuehler, T., Drettakis, G.: 3D Gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics42(4) (Jul 2023)
2023
-
[32]
In: Conference on Robot Learning (2024)
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E.P., Sanketi, P.R., Vuong, Q., et al.: OpenVLA: An open- source vision-language-action model. In: Conference on Robot Learning (2024)
2024
-
[33]
In: International Conference on Autonomous Agents
Kitano, H., Asada, M., Kuniyoshi, Y., Noda, I., Osawa, E.: Robocup: The robot world cup initiative. In: International Conference on Autonomous Agents. pp. 340– 347 (1997)
1997
-
[34]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: HunyuanVideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
In: Thirty-seventh Conference on Neural Information Processing Systems (2023)
Li, J., Song, Z., Yang, B.: NVFi: Neural velocity fields for 3d physics learning from dynamic videos. In: Thirty-seventh Conference on Neural Information Processing Systems (2023)
2023
-
[36]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, J., Song, Z., Yang, B.: TRACE: Learning 3D Gaussian physical dynamics from multi-view videos. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8820–8829 (2025)
2025
-
[37]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, J., Song, Z., Zhou, S., Yang, B.: FreeGave: 3D physics learning from dynamic videos by Gaussian velocity. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12433–12443 (2025)
2025
-
[38]
arXiv preprint arXiv:2504.16693 (2025)
Li, W., Zhao, H., Yu, Z., Du, Y., Zou, Q., Hu, R., Xu, K.: PIN-WM: Learning physics-informed world models for non-prehensile manipulation. arXiv preprint arXiv:2504.16693 (2025)
-
[39]
A Comprehensive Survey on World Models for Embodied AI
Li, X., He, X., Zhang, L., Wu, M., Li, X., Liu, Y.: A comprehensive survey on world models for embodied AI. arXiv preprint arXiv:2510.16732 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
In: Inter- national Conference on Learning Representations (2019)
Li, Y., Wu, J., Tedrake, R., Tenenbaum, J.B., Torralba, A.: Learning particle dynamics for manipulating rigid bodies, deformable objects, and fluids. In: Inter- national Conference on Learning Representations (2019)
2019
-
[41]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al.: DeepSeek-V3 technical report. arXiv preprint arXiv:2412.19437 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
In: Advances in Neural Information Processing Systems
Liu, B., Zhu, Y., Gao, C., Feng, Y., Liu, Q., Zhu, Y., Stone, P.: LIBERO: bench- marking knowledge transfer for lifelong robot learning. In: Advances in Neural Information Processing Systems. NIPS ’23, Curran Associates Inc., Red Hook, NY, USA (2023)
2023
-
[43]
arXiv preprint arXiv:2210.13431 (2022)
Liu, H., Lee, L., Lee, K., Abbeel, P.: Instruction-following agents with multimodal transformer. arXiv preprint arXiv:2210.13431 (2022)
-
[44]
In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S. (eds.) Advances in Neural Information Processing Systems. vol. 36, pp. 34892–34916. Curran Associates, Inc. (2023)
2023
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, J., Zhang, R., Fang, H.S., Gou, M., Fang, H., Wang, C., Xu, S., Yan, H., Lu, C.: Target-referenced reactive grasping for dynamic objects. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8824–8833 (2023) PhysMani 19
2023
-
[46]
In: International Conference on Learning Representations (2023)
Liu, X., Gong, C., et al.: Flow straight and fast: Learning to generate and transfer data with rectified flow. In: International Conference on Learning Representations (2023)
2023
-
[47]
In: European Conference on Computer Vision
Lu, G., Zhang, S., Wang, Z., Liu, C., Lu, J., Tang, Y.: ManiGaussian: Dynamic Gaussian splatting for multi-task robotic manipulation. In: European Conference on Computer Vision. pp. 349–366 (2024)
2024
-
[48]
IEEE Transactions on Neural Networks and Learning Systems (2026)
Ma, Y., Song, Z., Zhuang, Y., Hao, J., King, I.: A survey on vision–language–action models for embodied AI. IEEE Transactions on Neural Networks and Learning Systems (2026)
2026
-
[49]
Autonomous Robots43(5), 1241–1256 (2019)
Marturi, N., Kopicki, M., Rastegarpanah, A., Rajasekaran, V., Adjigble, M., Stolkin, R., Leonardis, A., Bekiroglu, Y.: Dynamic grasp and trajectory planning for moving objects. Autonomous Robots43(5), 1241–1256 (2019)
2019
-
[50]
IEEE Robotics and Automation Letters7(3), 7327–7334 (2022)
Mees, O., Hermann, L., Rosete-Beas, E., Burgard, W.: CALVIN: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks. IEEE Robotics and Automation Letters7(3), 7327–7334 (2022)
2022
-
[51]
Motamed, S., Culp, L., Swersky, K., Jaini, P., Geirhos, R.: Do generative video models understand physical principles? In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 948–958 (2026)
2026
-
[52]
In: Conference on Robot Learning
Noh, D., Kong, D., Zhao, M., Lizarraga, A., Xie, J., Wu, Y.N., Hong, D.: Latent adaptive planner for dynamic manipulation. In: Conference on Robot Learning. pp. 2430–2448 (2025)
2025
-
[53]
In: Proceedings of Robotics: Science and Systems
Octo Model Team, Ghosh, D., Walke, H., Pertsch, K., Black, K., Mees, O., Dasari, S., Hejna, J., Xu, C., Luo, J., Kreiman, T., Tan, Y., Sanketi, P., Vuong, Q., Xiao, T., Sadigh, D., Finn, C., Levine, S.: Octo: An open-source generalist robot policy. In: Proceedings of Robotics: Science and Systems. Delft, Netherlands (2024)
2024
-
[54]
Qwen Team: Qwen2.5-VL Technical Report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
arXiv preprint arXiv:2505.04769 (2025)
Sapkota, R., Cao, Y., Roumeliotis, K.I., Karkee, M.: Vision-language-action models: Concepts, progress, applications and challenges. arXiv preprint arXiv:2505.04769 (2025)
-
[56]
In: Conference on Robot Learning
Shridhar, M., Manuelli, L., Fox, D.: Perceiver-Actor: A multi-task transformer for robotic manipulation. In: Conference on Robot Learning. pp. 785–799 (2023)
2023
-
[57]
arXiv preprint arXiv:2511.23429 (2025)
Tang, J., Liu, J., Li, J., Wu, L., Yang, H., Zhao, P., Gong, S., Yuan, X., Shao, S., Zhang, L., et al.: Hunyuan-gamecraft-2: Instruction-following interactive game world model. arXiv preprint arXiv:2511.23429 (2025)
-
[58]
In: Advances in Neural Information Processing Systems
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, L., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems. pp. 6000–6010. NIPS’17, Curran Associates Inc., Red Hook, NY, USA (2017)
2017
-
[59]
In: Conference on Robot Learning
Walke, H.R., Black, K., Zhao, T.Z., Vuong, Q., Zheng, C., Hansen-Estruch, P., He, A.W., Myers, V., Kim, M.J., Du, M., et al.: BridgeData v2: A dataset for robot learning at scale. In: Conference on Robot Learning. pp. 1723–1736 (2023)
2023
-
[60]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan Team, Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
arXiv preprint arXiv:2601.22153 (2026)
Xie, H., Wen, B., Zheng, J., Chen, Z., Hong, F., Diao, H., Liu, Z.: DynamicVLA: A vision-language-action model for dynamic object manipulation. arXiv preprint arXiv:2601.22153 (2026)
-
[62]
Yang, A., Yu, B., Li, C., Liu, D., Huang, F., Huang, H., Jiang, J., Tu, J., Zhang, J., Zhou, J., Lin, J., Dang, K., Yang, K., Yu, L., Li, M., Sun, M., Zhu, Q., Men, 20 P. Yun et al. R., He, T., Xu, W., Yin, W., Yu, W., Qiu, X., Ren, X., Yang, X., Li, Y., Xu, Z., Zhang, Z.: Qwen2.5-1m technical report. arXiv preprint arXiv:2501.15383 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
In: International Conference on Learning Representations the 2nd Workshop on World Models: Un- derstanding, Modelling and Scaling (2026)
Ye, S., Ge, Y., Zheng, K., Gao, S., Yu, S., Kurian, G., Indupuru, S., Tan, Y.L., Zhu, C., Xiang, J., et al.: World action models are zero-shot policies. In: International Conference on Learning Representations the 2nd Workshop on World Models: Un- derstanding, Modelling and Scaling (2026)
2026
-
[64]
arXiv preprint arXiv:2509.19012 (2025)
Zhang, D., Sun, J., Hu, C., Wu, X., Yuan, Z., Zhou, R., Shen, F., Zhou, Q.: Pure vision language action (VLA) models: A comprehensive survey. arXiv preprint arXiv:2509.19012 (2025)
-
[65]
IEEE Robotics and Automation Letters10(6), 5209–5216 (2025)
Zhang, Y., Wang, R., Chen, X.: Dynamic behavior cloning with temporal feature prediction: Enhancing robotic arm manipulation in moving object tasks. IEEE Robotics and Automation Letters10(6), 5209–5216 (2025)
2025
-
[66]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Zhou, S., Wang, H., Cheng, H., Li, J., Wang, D., Jiang, J., Jin, Y., Huang, J., Mao, S., Liu, S., Yang, Y., Song, H., Wei, S., Zhang, Z., Wang, B., Wang, Z., Zou, C., Yang, B.: PhysInOne: Visual Physics Learning and Reasoning in One Suite. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 33131–33142 (2026)
2026
-
[67]
IEEE Transactions on Industrial Electronics71(7), 7466–7476 (2023)
Zhou, Y., Sun, G., Miao, Y., Zhang, Y., Chen, X., Wang, H.: Spatiotemporal optimal trajectory planning for safe planar manipulation of a moving object. IEEE Transactions on Industrial Electronics71(7), 7466–7476 (2023)
2023
-
[68]
2024.Is Sora a world simulator? A comprehensive survey on general world models and beyond
Zhu, Z., Wang, X., Zhao, W., Min, C., Li, B., Deng, N., Dou, M., Wang, Y., Shi, B., Wang, K., et al.: Is Sora a world simulator? a comprehensive survey on general world models and beyond. arXiv preprint arXiv:2405.03520 (2024)
-
[69]
In: Conference on Robot Learning
Zitkovich, B., Yu, T., Xu, S., Xu, P., Xiao, T., Xia, F., Wu, J., Wohlhart, P., Welker, S., Wahid, A., et al.: RT-2: Vision-language-action models transfer web knowledge to robotic control. In: Conference on Robot Learning. pp. 2165–2183 (2023) PhysMani 21 A Appendix A.1 Details of Physics-principled 3D Gaussian World Model Canonical 3D Gaussian Module: A...
2023
-
[70]
+λ ssim(1−ℓ ssim(I c 0, ˆI c 0)) + (1−λ ssim)ℓ1(Dc 0, ˆDc
-
[71]
basketball: x: [0.0, 0.3], y: [-0.5, 0.5], z: 0.8
+λ ssim(1−ℓ ssim(Dc 0, ˆDc 0)), (5) where{( ˆI c 0, ˆDc 0)}C c=1 are rendered RGB/Ds from canonical 3D Gaussians and λssim = 0.2. It takes about 15s on an RTX 4090 for PhysMani-Bench. 𝒈𝟎 ([1, 3])Positional Embedding ([1, 51])MLP(51, 128), ReLUMLP(128,128), ReLUMLP(128,128), ReLUConcatenate ([N,128+51])MLP(179, 128),ReLUMLP(128, 16)MLP(16, 64), ReLUMLP(64,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.