Closed Loop Dynamic Driving Data Mixture for Real-Synthetic Co-Training
Pith reviewed 2026-05-21 04:42 UTC · model grok-4.3
The pith
Closed-loop simulation feedback dynamically optimizes real-synthetic data mixtures for better autonomous driving performance with fewer samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
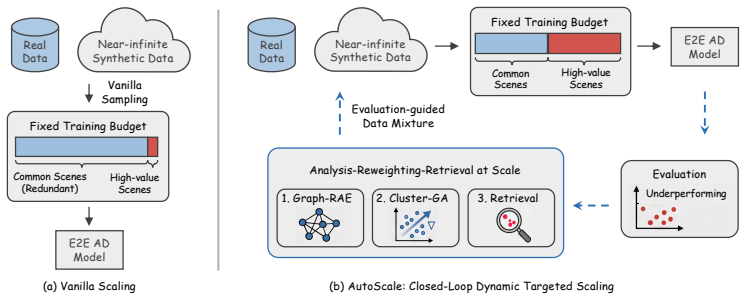
AutoScale formulates data mixture as a dynamic optimization process that iteratively adjusts scene types and quantities to maximize model performance using closed-loop evaluation feedback. It uses Graph Regularized AutoEncoder to represent driving scenes, Cluster-aware Gradient Ascent to estimate cluster importance and reweighting, and cluster-guided vector retrieval to select high-value synthetic samples. Experiments on NavSim show this outperforms vanilla co-training and cross-domain baselines while delivering better results with fewer synthetic samples under constrained budgets.
What carries the argument
The closed-loop data engine that unifies scene representation, cluster-wise importance estimation from evaluation feedback, and retrieval to dynamically adjust the real-synthetic training mixture.
Load-bearing premise
That signals from running the model in simulation reliably identify which scene clusters are most worth supplementing with synthetic data and that those choices improve performance on real data without creating new mismatches.
What would settle it
Training a model with the AutoScale mixture and then measuring its performance on a large set of real-world driving logs; if accuracy or robustness falls below that of a model trained with a fixed or random synthetic mixture, the central claim is falsified.
Figures





read the original abstract
Data scaling is fundamental to modern deep learning, and grows increasingly critical as autonomous driving shifts to end-to-end learning. Real-world driving data is expensive to annotate and scene-biased, making real-synthetic co-training with near-infinite synthetic data a promising direction. However, naively incorporating all available synthetic data is inefficient and leads to distribution shifts, and optimizing data mixture under practical training budgets remains a critical yet under-explored problem. In this sense, we claim that the mixture of training data requires clear guidance in terms of scene types and quantities. Particularly in this work, we conceptualize the data mixture approximately as a dynamic optimization process that iteratively adjusts the training data mixture to maximize model performance, guided by closed-loop evaluation feedback, and propose AutoScale, a fully automated closed-loop data engine unifying scene representation, data mixture optimization and retrieval, as well as model training and evaluation. Specifically, we propose Graph Regularized AutoEncoder (Graph-RAE) for driving scene representations, introduce Cluster-aware Gradient Ascent (Cluster-GA) for cluster-wise importance estimation and reweighting, and perform cluster-guided vector retrieval to select high-value samples. Experiments on NavSim demonstrate that AutoScale outperforms vanilla co-training and cross-domain baselines, achieving better performance with fewer synthetic samples under constrained budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AutoScale, a closed-loop data engine for real-synthetic co-training in autonomous driving. It introduces Graph Regularized AutoEncoder (Graph-RAE) for scene representations, Cluster-aware Gradient Ascent (Cluster-GA) for cluster-wise importance estimation and reweighting, and cluster-guided vector retrieval to select high-value samples. The central claim is that this dynamic optimization of data mixtures, guided by closed-loop NavSim feedback, outperforms vanilla co-training and cross-domain baselines while achieving better performance with fewer synthetic samples under constrained budgets.
Significance. If the results hold under rigorous validation, the work could meaningfully advance efficient data scaling for end-to-end driving models by automating mixture optimization. The unification of representation learning, gradient-based reweighting, and retrieval into a closed-loop engine addresses a practical bottleneck in real-synthetic co-training, with potential for broader impact in data-efficient training regimes.
major comments (3)
- [Abstract and Experimental Results] Abstract and Experimental Results: the reported gains on NavSim lack details on statistical significance testing, exact baseline implementations, data exclusion rules, error bars, or number of runs. Without these, it is difficult to assess whether the improvements with fewer samples are robust or could be explained by variance in training or evaluation.
- [Method (Cluster-GA and retrieval)] Method section on Cluster-GA: cluster importance weights and retrieval criteria appear derived from the same data distribution being optimized, and both gradient ascent steps and final performance measurement occur inside NavSim. This raises a load-bearing concern that reported gains may reflect fitting to simulator-specific artifacts rather than transferable improvements; an external hold-out (real data or alternate simulator) is needed to break potential circularity.
- [Experimental Results] Experimental Results: cluster definitions and the number of gradient ascent steps are described without ablation on their sensitivity or post-hoc selection criteria. If these choices were tuned on the evaluation distribution, the cross-domain and budget-constrained claims require re-validation with fixed, pre-specified hyperparameters.
minor comments (2)
- [Method] Notation for Graph-RAE loss terms and the precise formulation of the closed-loop objective could be clarified with an explicit equation relating importance weights to the performance feedback signal.
- [Figures] Figure captions and axis labels in the NavSim results plots should explicitly state the metric (e.g., success rate, collision rate) and the exact synthetic sample budget used for each curve.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications from the manuscript and indicating planned revisions where appropriate to improve rigor and transparency.
read point-by-point responses
-
Referee: [Abstract and Experimental Results] Abstract and Experimental Results: the reported gains on NavSim lack details on statistical significance testing, exact baseline implementations, data exclusion rules, error bars, or number of runs. Without these, it is difficult to assess whether the improvements with fewer samples are robust or could be explained by variance in training or evaluation.
Authors: We agree that additional statistical details would strengthen the presentation of results. In the revised manuscript we will report error bars computed over multiple independent training runs (specifying the exact number of runs and random seeds), include statistical significance tests (such as paired t-tests or Wilcoxon signed-rank tests) between AutoScale and the baselines, and expand the experimental section to describe exact baseline implementations, data exclusion criteria, and evaluation protocols. revision: yes
-
Referee: [Method (Cluster-GA and retrieval)] Method section on Cluster-GA: cluster importance weights and retrieval criteria appear derived from the same data distribution being optimized, and both gradient ascent steps and final performance measurement occur inside NavSim. This raises a load-bearing concern that reported gains may reflect fitting to simulator-specific artifacts rather than transferable improvements; an external hold-out (real data or alternate simulator) is needed to break potential circularity.
Authors: We acknowledge the validity of the circularity concern. The closed-loop design intentionally uses NavSim feedback to guide data mixture optimization for the real-synthetic co-training task, and cross-domain baselines are already included to probe generalization. To further mitigate simulator-specific artifacts, the revision will add an explicit discussion of potential biases together with results on an external hold-out (either a real-world driving dataset or an alternate simulator) to demonstrate that the selected mixtures transfer beyond the optimization loop. revision: partial
-
Referee: [Experimental Results] Experimental Results: cluster definitions and the number of gradient ascent steps are described without ablation on their sensitivity or post-hoc selection criteria. If these choices were tuned on the evaluation distribution, the cross-domain and budget-constrained claims require re-validation with fixed, pre-specified hyperparameters.
Authors: We clarify that cluster definitions are derived directly from the Graph-RAE latent space on the training distribution and that the number of gradient ascent steps was chosen according to convergence behavior observed in preliminary runs, not tuned on the final evaluation set. In the revision we will add sensitivity ablations on both the number of clusters and the number of ascent steps, performed with fixed, pre-specified hyperparameters, and will re-validate the budget-constrained and cross-domain claims under these fixed settings. revision: yes
Circularity Check
No significant circularity; closed-loop optimization uses external simulator feedback as objective
full rationale
The paper's derivation chain conceptualizes data mixture as an iterative optimization guided by closed-loop NavSim evaluation feedback, then introduces Graph-RAE for scene representation, Cluster-GA for importance estimation, and vector retrieval for sample selection. These steps are algorithmic proposals whose outputs (mixture weights, selected samples) are not equivalent to their inputs by construction; the performance signal is generated by running the trained model in simulation, which is an independent measurement step rather than a renaming or self-definition. No self-citations are invoked as load-bearing uniqueness theorems, no ansatz is smuggled, and no fitted parameter is relabeled as a prediction. Experiments compare against vanilla co-training and cross-domain baselines on the NavSim benchmark, providing an external anchor for the reported gains. The derivation remains self-contained; concerns about simulator-specific artifacts belong to generalization risk, not circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- cluster importance weights
axioms (2)
- domain assumption Driving scenes admit useful low-dimensional representations via graph-regularized autoencoders that preserve structural relationships
- domain assumption Closed-loop simulation feedback provides reliable guidance for selecting training data that improves real-world generalization
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We conceptualize the data mixture approximately as a dynamic optimization process that iteratively adjusts the training data mixture to maximize model performance, guided by closed-loop evaluation feedback
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2506.08228 , year=
Mustafa Baniodeh, Kratarth Goel, Scott Ettinger, Carlos Fuertes, Ari Seff, Tim Shen, Cole Gulino, Chenjie Yang, Ghassen Jerfel, Dokook Choe, et al. Scaling laws of motion forecasting and planning–technical report.arXiv preprint arXiv:2506.08228, 2025
-
[2]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
work page 2020
-
[4]
Pseudo-simulation for autonomous driving
Wei Cao, Marcel Hallgarten, Tianyu Li, Daniel Dauner, Xunjiang Gu, Caojun Wang, Yakov Miron, Marco Aiello, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, Andreas Geiger, and Kashyap Chitta. Pseudo-simulation for autonomous driving. InProceedings of the Conference on Robot Learning (CoRL), 2025
work page 2025
-
[5]
Li Chen, Penghao Wu, Kashyap Chitta, Bernhard Jaeger, Andreas Geiger, and Hongyang Li. End-to-end autonomous driving: Challenges and frontiers.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024
work page 2024
-
[6]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InProceedings of the International conference on machine learning (ICML), 2020
work page 2020
-
[7]
Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023
work page 2023
-
[8]
Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking
Daniel Dauner, Marcel Hallgarten, Tianyu Li, Xinshuo Weng, Zhiyu Huang, Zetong Yang, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, Andreas Geiger, and Kashyap Chitta. Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[9]
Shizhe Diao, Yu Yang, Yonggan Fu, Xin Dong, Dan Su, Markus Kliegl, Zijia Chen, Peter Belcak, Yoshi Suhara, Hongxu Yin, et al. Nemotron-climb: Clustering-based iterative data mixture bootstrapping for language model pre-training. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[10]
Realgen: Retrieval augmented generation for controllable traffic scenarios
Wenhao Ding, Yulong Cao, Ding Zhao, Chaowei Xiao, and Marco Pavone. Realgen: Retrieval augmented generation for controllable traffic scenarios. InProceedings of the European Conference on Computer Vision (ECCV), 2024
work page 2024
-
[11]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. InProceedings of the International Conference on Learning Representations (ICLR), 2020
work page 2020
-
[12]
Doge: Domain reweighting with generalization estimation
Simin Fan, Matteo Pagliardini, and Martin Jaggi. Doge: Domain reweighting with generalization estimation. InProceedings of the International conference on machine learning (ICML), 2024
work page 2024
-
[13]
Magicdrive- v2: High-resolution long video generation for autonomous driving with adaptive control
Ruiyuan Gao, Kai Chen, Bo Xiao, Lanqing Hong, Zhenguo Li, and Qiang Xu. Magicdrive- v2: High-resolution long video generation for autonomous driving with adaptive control. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
work page 2025
-
[14]
MagicDrive: Street view generation with diverse 3d geometry control
Ruiyuan Gao, Kai Chen, Enze Xie, Lanqing Hong, Zhenguo Li, Dit-Yan Yeung, and Qiang Xu. MagicDrive: Street view generation with diverse 3d geometry control. InProceedings of the International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[15]
Vista: A generalizable driving world model with high fidelity and versatile controllability
Shenyuan Gao, Jiazhi Yang, Li Chen, Kashyap Chitta, Yihang Qiu, Andreas Geiger, Jun Zhang, and Hongyang Li. Vista: A generalizable driving world model with high fidelity and versatile controllability. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 10
work page 2024
-
[16]
Guillermo Garcia-Cobo, Maximilian Igl, Peter Karkus, Zhejun Zhang, Michael Watson, Yuxiao Chen, Boris Ivanovic, and Marco Pavone. Road: Rollouts as demonstrations for closed-loop supervised fine-tuning of autonomous driving policies.arXiv preprint arXiv:2512.01993, 2025
-
[17]
Unraveling the effects of synthetic data on end-to-end autonomous driving
Junhao Ge, Zuhong Liu, Longteng Fan, Yifan Jiang, Jiaqi Su, Yiming Li, Zhejun Zhang, and Siheng Chen. Unraveling the effects of synthetic data on end-to-end autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
work page 2025
-
[18]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2016
work page 2016
-
[19]
GAIA-1: A Generative World Model for Autonomous Driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, Lewei Lu, Xiaosong Jia, Qiang Liu, Jifeng Dai, Yu Qiao, and Hongyang Li. Planning-oriented autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[21]
Étude comparative de la distribution florale dans une portion des alpes et des jura
Paul Jaccard. Étude comparative de la distribution florale dans une portion des alpes et des jura. Bulletin de la Société V audoise des Sciences Naturelles, 1901
work page 1901
-
[22]
Vad: Vectorized scene representation for efficient autonomous driving
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representation for efficient autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
work page 2023
-
[23]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[24]
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics (ToG), 2023
work page 2023
-
[25]
Supervised contrastive learning
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
work page 2020
-
[26]
Adam: a method for stochastic optimization
Diederik P Kingma and Jimmy Ba. Adam: a method for stochastic optimization. InProceedings of the International Conference on Learning Representations (ICLR), 2015
work page 2015
-
[27]
Mtgs: Multi-traversal gaussian splatting.arXiv preprint arXiv:2503.12552, 2025
Tianyu Li, Yihang Qiu, Zhenhua Wu, Carl Lindström, Peng Su, Matthias Nießner, and Hongyang Li. Mtgs: Multi-traversal gaussian splatting.arXiv preprint arXiv:2503.12552, 2025
-
[28]
Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving
Yongkang Li, Kaixin Xiong, Xiangyu Guo, Fang Li, Sixu Yan, Gangwei Xu, Lijun Zhou, Long Chen, Haiyang Sun, Bing Wang, et al. Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving. InProceedings of the International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[29]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving
Bencheng Liao, Shaoyu Chen, Haoran Yin, Bo Jiang, Cheng Wang, Sixu Yan, Xinbang Zhang, Xiangyu Li, Ying Zhang, Qian Zhang, et al. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
work page 2025
-
[30]
Model-based policy adaptation for closed-loop end-to-end autonomous driving
Haohong Lin, Yunzhi Zhang, Wenhao Ding, Jiajun Wu, and Ding Zhao. Model-based policy adaptation for closed-loop end-to-end autonomous driving. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[31]
Regmix: Data mixture as regression for language model pre-training
Qian Liu, Xiaosen Zheng, Niklas Muennighoff, Guangtao Zeng, Longxu Dou, Tianyu Pang, Jing Jiang, and Min Lin. Regmix: Data mixture as regression for language model pre-training. InProceedings of the International Conference on Learning Representations (ICLR), 2025. 11
work page 2025
-
[32]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InProceedings of the International Conference on Learning Representations (ICLR), 2019
work page 2019
-
[33]
Enhui Ma, Lijun Zhou, Tao Tang, Zhan Zhang, Dong Han, Junpeng Jiang, Kun Zhan, Peng Jia, Xianpeng Lang, Haiyang Sun, et al. Unleashing generalization of end-to-end autonomous driving with controllable long video generation.arXiv preprint arXiv:2406.01349, 2024
-
[34]
Sim-and-real co-training: A simple recipe for vision-based robotic manipulation
Abhiram Maddukuri, Zhenyu Jiang, Lawrence Yunliang Chen, Soroush Nasiriany, Yuqi Xie, Yu Fang, Wenqi Huang, Zu Wang, Zhenjia Xu, Nikita Chernyadev, Scott Reed, Ken Goldberg, Ajay Mandlekar, Linxi Fan, and Yuke Zhu. Sim-and-real co-training: A simple recipe for vision-based robotic manipulation. InProceedings of Robotics: Science and Systems (RSS), 2025
work page 2025
-
[35]
Robocasa: Large-scale simulation of everyday tasks for generalist robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots. InProceedings of Robotics: Science and Systems (RSS), 2024
work page 2024
-
[36]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA, Johan Bjorck, Nikita Cherniadev Fernando Castañeda, Xingye Da, Runyu Ding, Linxi "Jim" Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, You L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InProceedings of the International conference on machine learning (ICML), 2021
work page 2021
-
[38]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer
Xuanchi Ren, Yifan Lu, Tianshi Cao, Ruiyuan Gao, Shengyu Huang, Amirmojtaba Sabour, Tianchang Shen, Tobias Pfaff, Jay Zhangjie Wu, Runjian Chen, et al. Cosmos-drive-dreams: Scalable synthetic driving data generation with world foundation models.arXiv preprint arXiv:2506.09042, 2025
-
[39]
Sparsedrive: End-to-end autonomous driving via sparse scene representation
Wenchao Sun, Xuewu Lin, Yining Shi, Chuang Zhang, Haoran Wu, and Sifa Zheng. Sparsedrive: End-to-end autonomous driving via sparse scene representation. InProceedings of the Interna- tional Conference on Robotics and Automation (ICRA), 2025
work page 2025
-
[40]
GigaWorld Team, Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Haoyun Li, Jiagang Zhu, Kerui Li, Mengyuan Xu, et al. Gigaworld-0: World models as data engine to empower embodied ai.arXiv preprint arXiv:2511.19861, 2025
-
[41]
Simscale: Learning to drive via real-world simulation at scale
Haochen Tian, Tianyu Li, Haochen Liu, Jiazhi Yang, Yihang Qiu, Guang Li, Junli Wang, Yinfeng Gao, Zhang Zhang, Liang Wang, et al. Simscale: Learning to drive via real-world simulation at scale. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2026
work page 2026
-
[42]
Yang Tian, Yuyin Yang, Yiman Xie, Zetao Cai, Xu Shi, Ning Gao, Hangxu Liu, Xuekun Jiang, Zherui Qiu, Feng Yuan, et al. Interndata-a1: Pioneering high-fidelity synthetic data for pre-training generalist policy.arXiv preprint arXiv:2511.16651, 2025
-
[43]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in neural information processing systems (NeurIPS), 2017
work page 2017
-
[45]
Drive- dreamer: Towards real-world-drive world models for autonomous driving
Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jiagang Zhu, and Jiwen Lu. Drive- dreamer: Towards real-world-drive world models for autonomous driving. InProceedings of the European Conference on Computer Vision (ECCV), 2024. 12
work page 2024
-
[46]
Panacea: Panoramic and controllable video generation for autonomous driving
Yuqing Wen, Yucheng Zhao, Yingfei Liu, Fan Jia, Yanhui Wang, Chong Luo, Chi Zhang, Tiancai Wang, Xiaoyan Sun, and Xiangyu Zhang. Panacea: Panoramic and controllable video generation for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2024
work page 2024
-
[47]
Data retrieval with importance weights for few-shot imitation learning
Amber Xie, Rahul Chand, Dorsa Sadigh, and Joey Hejna. Data retrieval with importance weights for few-shot imitation learning. InProceedings of the Conference on Robot Learning (CoRL), 2025
work page 2025
-
[48]
Doremi: Optimizing data mixtures speeds up language model pretraining
Sang Michael Xie, Hieu Pham, Xuanyi Dong, Nan Du, Hanxiao Liu, Yifeng Lu, Percy S Liang, Quoc V Le, Tengyu Ma, and Adams Wei Yu. Doremi: Optimizing data mixtures speeds up language model pretraining. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[49]
Chameleon: A flexible data-mixing framework for language model pretraining and finetuning
Wanyun Xie, Francesco Tonin, and V olkan Cevher. Chameleon: A flexible data-mixing framework for language model pretraining and finetuning. InProceedings of the International conference on machine learning (ICML), 2025
work page 2025
-
[50]
Zebin Xing, Xingyu Zhang, Yang Hu, Bo Jiang, Tong He, Qian Zhang, Xiaoxiao Long, and Wei Yin. Goalflow: Goal-driven flow matching for multimodal trajectories generation in end-to-end autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2025
work page 2025
-
[51]
Data mixing laws: Optimizing data mixtures by predicting language modeling performance
Jiasheng Ye, Peiju Liu, Tianxiang Sun, Jun Zhan, Yunhua Zhou, and Xipeng Qiu. Data mixing laws: Optimizing data mixtures by predicting language modeling performance. InProceedings of the International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[52]
Diffusion-based planning for autonomous driving with flexible guidance
Yinan Zheng, Ruiming Liang, Kexin Zheng, Jinliang Zheng, Liyuan Mao, Jianxiong Li, Weihao Gu, Rui Ai, Shengbo Eben Li, Xianyuan Zhan, and Jingjing Liu. Diffusion-based planning for autonomous driving with flexible guidance. InProceedings of the International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[53]
Yupeng Zheng, Pengxuan Yang, Zhongpu Xia, Qichao Zhang, Yuhang Zheng, Songen Gu, Bu Jin, Teng Zhang, Ben Lu, Chao Han, et al. Data scaling laws for imitation learning-based end-to-end autonomous driving.arXiv preprint arXiv:2412.02689, 2024. 13 Technical appendices and supplementary material This supplementary material presents implementation and evaluati...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.