Physically Viable World Models: A Case for Query-Conditioned Embodied AI
Pith reviewed 2026-06-29 06:52 UTC · model grok-4.3
The pith
Embodied AI requires world models that identify the simplest physical abstraction sufficient to answer an intervention query rather than predict observations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
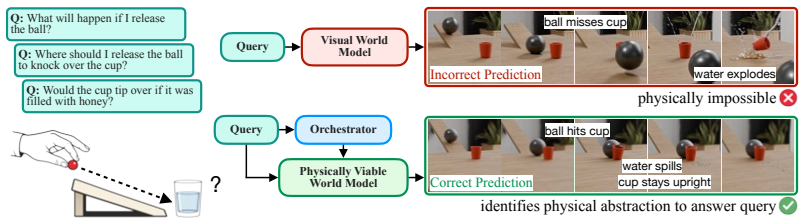
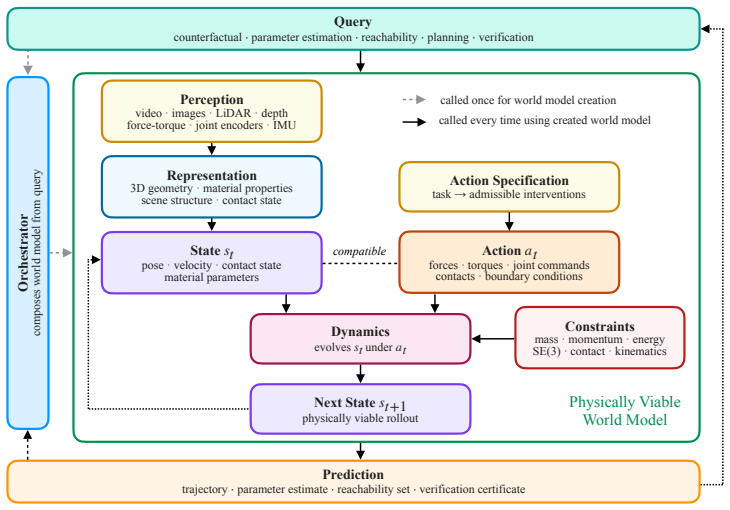
World models for embodied AI must be physically viable: constructed to answer intervention queries by representing the physical structure governing action outcomes, rather than merely predicting future observations. Existing observation-predictive world models can produce visually plausible but physically wrong rollouts. This failure is structural; distinct physical systems can look identical yet diverge under intervention. The right abstraction is not the most detailed model of the world, but the simplest model that preserves the distinctions relevant to the query. Such a model comprises modular components, including environment representation, latent state and parameter estimation, action
What carries the argument
The query-conditioned physically viable world model, which identifies the simplest physical abstraction sufficient for an intervention query and assembles it from modular components via an autonomous orchestrator.
If this is right
- Models remain interpretable because each component can be verified independently against the query.
- Outputs become auditable because the model must preserve only the distinctions relevant to the intervention.
- When closed-form physics is unavailable the transition model may be analytic, simulated, learned, or hybrid provided it keeps the structure that determines outcomes.
- The approach supplies an explicit feasibility test: an existing model is viable only if it preserves the distinctions relevant to the query.
- Demonstrations show the method succeeding on queries where current systems fail.
Where Pith is reading between the lines
- The modular decomposition could support incremental verification of safety properties in robotic planning without requiring full physics simulation.
- Benchmarks focused on intervention divergence might replace or supplement current visual-prediction metrics in embodied-AI evaluation.
- An orchestrator that switches abstractions per query could reduce computational cost by activating only the physics needed for the immediate decision.
- The same principle of minimal sufficient abstraction might apply to other domains where passive prediction diverges from active control, such as process control or interactive simulation.
Load-bearing premise
Distinct physical systems can look identical from observations yet produce different results under intervention, so models built only on observation prediction are structurally insufficient.
What would settle it
Controlled benchmarks that fix the visible scene while varying latent physics, where an observation-predictive model recommends an infeasible action or mispredicts an interaction outcome.
Figures









read the original abstract
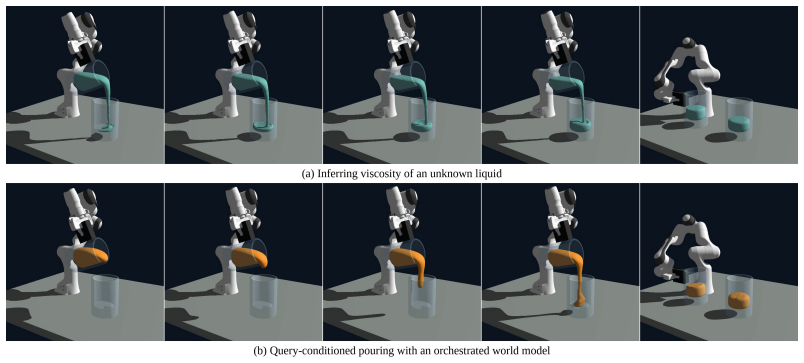
World models for embodied AI must be physically viable: constructed to answer intervention queries by representing the physical structure governing action outcomes, rather than merely predicting future observations. Existing observation-predictive world models can produce visually plausible but physically wrong rollouts. This failure is structural; distinct physical systems can look identical yet diverge under intervention. We expose this problem with controlled benchmarks that fix the visible scene while varying latent physics. We show that such models may recommend infeasible actions, mispredict interaction outcomes, or certify unsafe behavior. We argue that embodied AI requires world models that identify the simplest physical abstraction sufficient to answer an intervention query. Such a model comprises modular components, including environment representation, latent state and parameter estimation, action specification, interventional dynamics, and query-level response. An autonomous orchestrator should identify the relevant abstraction and compose compatible learned and structured components per query. When closed-form physics is unavailable, uncertain, or costly, the transition model may be analytic, simulated, learned, or hybrid, but it must preserve the structure that determines interventional outcomes. This decomposition makes the model interpretable, its components verifiable, and its outputs auditable against the query. It also provides a design principle for new world models and a feasibility test for existing ones: the right abstraction is not the most detailed model of the world, but the simplest model that preserves the distinctions relevant to the query. We demonstrate this approach on queries that existing systems fail to answer correctly, and outline how an orchestrator can dynamically assemble and adapt physically viable models for planning, control, and verification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that world models for embodied AI must be physically viable by representing the physical structure needed to answer intervention queries rather than merely predicting observations. It argues that observation-predictive models are structurally insufficient because distinct physical systems can produce identical observations yet diverge under interventions. The proposed solution is a modular decomposition (environment representation, latent state/parameter estimation, action specification, interventional dynamics, query-level response) assembled by an autonomous orchestrator that selects the simplest sufficient abstraction per query. The manuscript asserts that this yields interpretable, verifiable models and demonstrates the approach on queries where existing systems fail, while outlining a design principle and feasibility test.
Significance. The emphasis on interventional structure over observational prediction aligns with causal reasoning principles and could guide more reliable planning and verification in embodied AI if the modular decomposition is made concrete. The query-conditioned abstraction idea provides a useful design heuristic. However, the manuscript offers only a high-level conceptual argument with no derivations, benchmarks, or implementations, so any significance remains prospective rather than established.
major comments (3)
- [Abstract] Abstract: the definition of physically viable world models is constructed directly from the requirement to answer intervention queries ("constructed to answer intervention queries by representing the physical structure governing action outcomes"), so the proposed modular solution largely restates the problem definition rather than deriving an independent criterion or mechanism.
- [Abstract] Abstract: the manuscript states that controlled benchmarks are used to expose the structural failure of observation-predictive models and that the approach is demonstrated on queries where existing systems fail, yet no benchmark descriptions, datasets, quantitative results, or specific query examples are provided, leaving the central empirical claim unsupported.
- [Abstract] Abstract: the autonomous orchestrator is introduced as the component that identifies the relevant abstraction and composes learned/structured modules, but no architecture, selection algorithm, or adaptation procedure is specified, which is load-bearing for the feasibility of the overall proposal.
minor comments (1)
- [Abstract] Abstract: the phrase "when closed-form physics is unavailable, uncertain, or costly" introduces a qualification on transition models without clarifying how the orchestrator would detect or handle these cases.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which correctly identify that the manuscript is a high-level conceptual proposal rather than an empirical study. We address each point below, agreeing where the abstract overstates content and clarifying the intent of the definitional and architectural elements. Revisions will focus on precision in claims and scope.
read point-by-point responses
-
Referee: [Abstract] Abstract: the definition of physically viable world models is constructed directly from the requirement to answer intervention queries ("constructed to answer intervention queries by representing the physical structure governing action outcomes"), so the proposed modular solution largely restates the problem definition rather than deriving an independent criterion or mechanism.
Authors: The definition is deliberately tied to interventional capability because that is the distinguishing requirement for embodied AI. The modular decomposition supplies an independent mechanism by enumerating the minimal components (environment representation, latent state/parameter estimation, action specification, interventional dynamics, query-level response) whose composition must preserve query-relevant physical distinctions. This structure is not automatic in observation-predictive models and therefore constitutes a testable criterion. We will revise the abstract to separate the definitional premise from the modular criterion more explicitly. revision: partial
-
Referee: [Abstract] Abstract: the manuscript states that controlled benchmarks are used to expose the structural failure of observation-predictive models and that the approach is demonstrated on queries where existing systems fail, yet no benchmark descriptions, datasets, quantitative results, or specific query examples are provided, leaving the central empirical claim unsupported.
Authors: The referee is correct. The manuscript contains no datasets, quantitative results, or formal benchmark descriptions; the referenced "controlled benchmarks" and "demonstrations" are limited to illustrative thought experiments in the text. We will revise the abstract to remove or qualify all language implying empirical evaluation and to characterize the work accurately as a design principle with conceptual illustrations. revision: yes
-
Referee: [Abstract] Abstract: the autonomous orchestrator is introduced as the component that identifies the relevant abstraction and composes learned/structured modules, but no architecture, selection algorithm, or adaptation procedure is specified, which is load-bearing for the feasibility of the overall proposal.
Authors: We agree that no concrete architecture or algorithm for the orchestrator is provided. The paper advances a design principle and feasibility test rather than an implemented system; the orchestrator is therefore described only at the level of required functionality. We will revise the abstract and relevant sections to state explicitly that detailed orchestrator mechanisms constitute future work and to list the minimal interface properties any such component must satisfy. revision: partial
Circularity Check
Physically viable world models defined directly via intervention-query requirement
specific steps
-
self definitional
[Abstract]
"World models for embodied AI must be physically viable: constructed to answer intervention queries by representing the physical structure governing action outcomes, rather than merely predicting future observations. [...] We argue that embodied AI requires world models that identify the simplest physical abstraction sufficient to answer an intervention query. Such a model comprises modular components, including environment representation, latent state and parameter estimation, action specification, interventional dynamics, and query-level response."
The paper first defines physically viable models as those built to answer intervention queries, then claims embodied AI requires models with the precise components needed to fulfill that definition, rendering the architecture a direct restatement of the initial requirement rather than a derived result.
full rationale
The abstract explicitly defines 'physically viable' world models as those 'constructed to answer intervention queries' and then states that embodied AI 'requires' models with exactly the listed modular components for that purpose. This makes the central proposal equivalent to the problem statement by construction rather than an independent derivation. No equations or further technical steps are available in the provided text to inspect for additional reductions, and the logical observation that identical visuals can mask different physics is not itself circular. The overall score reflects partial circularity confined to the definitional framing.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Distinct physical systems can look identical yet diverge under intervention.
invented entities (1)
-
autonomous orchestrator
no independent evidence
Reference graph
Works this paper leans on
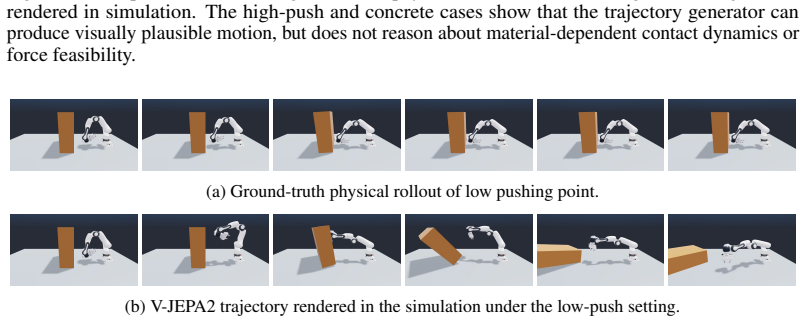
-
[1]
Jad Abou-Chakra, Krishan Rana, Feras Dayoub, and Niko Sünderhauf. Physically embod- ied Gaussian splatting: A realtime correctable world model for robotics.arXiv preprint arXiv:2406.10788, 2024
-
[2]
Artificial analysis text-to-video leaderboard (open-weights mod- els)
Artificial Analysis. Artificial analysis text-to-video leaderboard (open-weights mod- els). https://artificialanalysis.ai/video/leaderboard/text-to-video? open-weights=true, 2026. Accessed: 2026-04-27
2026
-
[3]
Artificial analysis text-to-video leaderboard (open-weights mod- els)
Artificial Analysis. Artificial analysis text-to-video leaderboard (open-weights mod- els). https://artificialanalysis.ai/video/leaderboard/image-to-video? open-weights=true, 2026. Accessed: 2026-04-27
2026
-
[4]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Genesis: A generative and universal physics engine for robotics and beyond, December 2024
Genesis Authors. Genesis: A generative and universal physics engine for robotics and beyond, December 2024
2024
-
[6]
Leonardo Barcellona, Andrii Zadaianchuk, Davide Allegro, Samuele Papa, Stefano Ghidoni, and Efstratios Gavves. Dream to manipulate: Compositional world models empowering robot imitation learning with imagination.arXiv preprint arXiv:2412.14957, 2024
-
[7]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual repre- sentations from video.arXiv preprint arXiv:2404.08471, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Interaction networks for learning about objects, relations and physics.Advances in neural information processing systems, 29, 2016
Peter Battaglia, Razvan Pascanu, Matthew Lai, Danilo Jimenez Rezende, et al. Interaction networks for learning about objects, relations and physics.Advances in neural information processing systems, 29, 2016
2016
-
[9]
Divergence-free smoothed particle hydrodynamics
Jan Bender and Dan Koschier. Divergence-free smoothed particle hydrodynamics. InProceed- ings of the 14th ACM SIGGRAPH/Eurographics symposium on computer animation, pages 147–155, 2015
2015
-
[10]
Enforcing analytic constraints in neural networks emulating physical systems.Physical review letters, 126(9):098302, 2021
Tom Beucler, Michael Pritchard, Stephan Rasp, Jordan Ott, Pierre Baldi, and Pierre Gentine. Enforcing analytic constraints in neural networks emulating physical systems.Physical review letters, 126(9):098302, 2021
2021
-
[11]
Kaifeng Bi, Lingxi Xie, Hengheng Zhang, Xin Chen, Xiaotao Gu, and Qi Tian. Pangu-Weather: A 3d high-resolution model for fast and accurate global weather forecast.arXiv preprint arXiv:2211.02556, 2022
-
[12]
A Compositional Object-Based Approach to Learning Physical Dynamics
Michael B. Chang, Tomer Ullman, Antonio Torralba, and Joshua B. Tenenbaum. A composi- tional object-based approach to learning physical dynamics. InInternational Conference on Learning Representations (ICLR), 2017. arXiv:1612.00341
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
PhysGen3D: Crafting a miniature interactive world from a single image
Boyuan Chen, Hanxiao Jiang, Shaowei Liu, Saurabh Gupta, Yunzhu Li, Hao Zhao, and Shenlong Wang. PhysGen3D: Crafting a miniature interactive world from a single image. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. arXiv:2503.20746
-
[14]
TransDreamer: Reinforcement learning with transformer world models
Chang Chen, Yi-Fu Wu, Jaesik Yoon, and Sungjin Ahn. TransDreamer: Reinforcement learning with transformer world models. InDeep Reinforcement Learning Workshop, NeurIPS 2021,
2021
-
[15]
Neural ordinary differential equations.Advances in neural information processing systems, 31, 2018
Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations.Advances in neural information processing systems, 31, 2018. 10
2018
-
[16]
Wei Chow, Jiageng Mao, Boyi Li, Daniel Seita, Vitor Guizilini, and Yue Wang. Physbench: Benchmarking and enhancing vision-language models for physical world understanding.arXiv preprint arXiv:2501.16411, 2025
-
[17]
Miles Cranmer, Sam Greydanus, Stephan Hoyer, Peter Battaglia, David Spergel, and Shirley Ho. Lagrangian neural networks. InICLR Workshop on Deep Differential Equations, 2020. arXiv:2003.04630
-
[18]
Discovering symbolic models from deep learning with inductive biases.Advances in neural information processing systems, 33:17429–17442, 2020
Miles Cranmer, Alvaro Sanchez Gonzalez, Peter Battaglia, Rui Xu, Kyle Cranmer, David Spergel, and Shirley Ho. Discovering symbolic models from deep learning with inductive biases.Advances in neural information processing systems, 33:17429–17442, 2020
2020
-
[19]
Facing off world model backbones: RNNs, transformers, and S4
Fei Deng, Junyeong Park, and Sungjin Ahn. Facing off world model backbones: RNNs, transformers, and S4. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. arXiv:2307.02064
-
[20]
Zihan Ding, Amy Zhang, Yuandong Tian, and Qinqing Zheng. Diffusion world model: Fu- ture modeling beyond step-by-step rollout for offline reinforcement learning.arXiv preprint arXiv:2402.03570, 2024
-
[21]
Daniel Freeman, Erik Frey, Anton Raichuk, Sertan Girgin, Igor Mordatch, and Olivier Bachem
C. Daniel Freeman, Erik Frey, Anton Raichuk, Sertan Girgin, Igor Mordatch, and Olivier Bachem. Brax – a differentiable physics engine for large scale rigid body simulation.arXiv preprint arXiv:2106.13281, 2021
-
[22]
Pddlstream: Integrating symbolic planners and blackbox samplers via optimistic adaptive planning
Caelan Reed Garrett, Tomás Lozano-Pérez, and Leslie Pack Kaelbling. Pddlstream: Integrating symbolic planners and blackbox samplers via optimistic adaptive planning. InProceedings of the international conference on automated planning and scheduling, volume 30, pages 440–448, 2020
2020
-
[23]
Sam Greydanus, Misko Dzamba, and Jason Yosinski. Hamiltonian neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), 2019. arXiv:1906.01563
-
[24]
"PhyWorldBench": A Comprehensive Evaluation of Physical Realism in Text-to-Video Models
Jing Gu, Xian Liu, Yu Zeng, Ashwin Nagarajan, Fangrui Zhu, Daniel Hong, Yue Fan, Qianqi Yan, Kaiwen Zhou, Ming-Yu Liu, et al. " phyworldbench": A comprehensive evaluation of physical realism in text-to-video models.arXiv preprint arXiv:2507.13428, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Xuyang Guo, Jiayan Huo, Zhenmei Shi, Zhao Song, Jiahao Zhang, and Jiale Zhao. T2vphysbench: A first-principles benchmark for physical consistency in text-to-video gen- eration.arXiv preprint arXiv:2505.00337, 2025
-
[26]
MaskViT: Masked visual pre-training for video prediction
Agrim Gupta, Stephen Tian, Yunzhi Zhang, Jiajun Wu, Roberto Martín-Martín, and Fei-Fei Li. MaskViT: Masked visual pre-training for video prediction. InInternational Conference on Learning Representations (ICLR), 2023. arXiv:2206.11894
-
[27]
Recurrent world models facilitate policy evolution.Ad- vances in neural information processing systems, 31, 2018
David Ha and Jürgen Schmidhuber. Recurrent world models facilitate policy evolution.Ad- vances in neural information processing systems, 31, 2018
2018
-
[28]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al. Ltx-2: Efficient joint audio-visual foundation model.arXiv preprint arXiv:2601.03233, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[31]
Learning latent dynamics for planning from pixels
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. InInternational conference on machine learning, pages 2555–2565. PMLR, 2019
2019
-
[32]
Mastering Atari with Discrete World Models
Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering Atari with discrete world models. InInternational Conference on Learning Representations (ICLR), 2021. arXiv:2010.02193. 11
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Mastering diverse control tasks through world models.Nature, 640(8059):647–653, 2025
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse control tasks through world models.Nature, 640(8059):647–653, 2025
2025
-
[35]
TD-MPC2: Scalable, Robust World Models for Continuous Control
Nicklas Hansen, Hao Su, and Xiaolong Wang. TD-MPC2: Scalable, robust world models for continuous control. InInternational Conference on Learning Representations (ICLR), 2024. arXiv:2310.16828
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
DiffTaichi: Differentiable programming for physical simulation
Yuanming Hu, Luke Anderson, Tzu-Mao Li, Qi Sun, Nathan Carr, Jonathan Ragan-Kelley, and Frédo Durand. DiffTaichi: Differentiable programming for physical simulation. InInternational Conference on Learning Representations (ICLR), 2020. arXiv:1910.00935
-
[37]
Siqiao Huang, Jialong Wu, Qixing Zhou, Shangchen Miao, and Mingsheng Long. Vid2World: Crafting video diffusion models to interactive world models.arXiv preprint arXiv:2505.14357, 2025
- [38]
-
[39]
Planning with Diffusion for Flexible Behavior Synthesis
Michael Janner, Yilun Du, Joshua B. Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis. InProceedings of the 39th International Conference on Machine Learning (ICML), volume 162 ofProceedings of Machine Learning Research, pages 9902–9915. PMLR, 2022. arXiv:2205.09991
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[40]
gradSim: Differentiable simulation for system identification and visuomotor control
Krishna Murthy Jatavallabhula, Miles Macklin, Florian Golemo, Vikram V oleti, Linda Petrini, Martin Weiss, Breandan Considine, Jerome Parent-Levesque, Kevin Xie, Kenny Erleben, Liam Paull, Florian Shkurti, Derek Nowrouzezahrai, and Sanja Fidler. gradSim: Differentiable simulation for system identification and visuomotor control. InInternational Conference...
-
[41]
Integrated task and motion planning in belief space.The International Journal of Robotics Research, 32(9-10):1194–1227, 2013
Leslie Pack Kaelbling and Tomás Lozano-Pérez. Integrated task and motion planning in belief space.The International Journal of Robotics Research, 32(9-10):1194–1227, 2013
2013
-
[42]
How Far is Video Generation from World Model: A Physical Law Perspective
Bingyi Kang, Yang Yue, Rui Lu, Zhijie Lin, Yang Zhao, Kaixin Wang, Gao Huang, and Jiashi Feng. How far is video generation from world model: A physical law perspective.arXiv preprint arXiv:2411.02385, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3D Gaussian Splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), 2023. arXiv:2308.04079
-
[44]
Contrastive learning of structured world mod- els
Thomas Kipf, Elise van der Pol, and Max Welling. Contrastive learning of structured world mod- els. InInternational Conference on Learning Representations (ICLR), 2020. arXiv:1911.12247
-
[45]
Remi Lam, Alvaro Sanchez-Gonzalez, Matthew Willson, Peter Wirnsberger, Meire Fortunato, Ferran Alet, Suman Ravuri, Timo Ewalds, Zach Eaton-Rosen, Weihua Hu, Alexander Merose, Stephan Hoyer, George Holland, Oriol Vinyals, Jacklynn Stott, Alexander Pritzel, Shakir Mohamed, and Peter Battaglia. GraphCast: Learning skillful medium-range global weather forecas...
-
[46]
Learning Particle Dynamics for Manipulating Rigid Bodies, Deformable Objects, and Fluids
Yunzhu Li, Jiajun Wu, Russ Tedrake, Joshua B. Tenenbaum, and Antonio Torralba. Learning particle dynamics for manipulating rigid bodies, deformable objects, and fluids. InInternational Conference on Learning Representations (ICLR), 2019. arXiv:1810.01566
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[47]
Ltx-2 model card.https://huggingface.co/Lightricks/LTX-2, 2026
Lightricks. Ltx-2 model card.https://huggingface.co/Lightricks/LTX-2, 2026
2026
-
[48]
arXiv preprint arXiv:2306.06561 , year=
Yu-Ren Liu, Biwei Huang, Zhengmao Zhu, Honglong Tian, Mingming Gong, Yang Yu, and Kun Zhang. Learning world models with identifiable factorization.arXiv preprint arXiv:2306.06561, 2023. 12
-
[49]
Zhuoman Liu, Weicai Ye, Yan Luximon, Pengfei Wan, and Di Zhang. PhysFlow: Unleashing the potential of multi-modal foundation models and video diffusion for 4d dynamic physical scene simulation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. arXiv:2411.14423
-
[50]
Object-centric learning with slot attention
Francesco Locatello, Dirk Weissenborn, Thomas Unterthiner, Aravindh Mahendran, Georg Heigold, Jakob Uszkoreit, Alexey Dosovitskiy, and Thomas Kipf. Object-centric learning with slot attention. InAdvances in Neural Information Processing Systems (NeurIPS), 2020. arXiv:2006.15055
-
[51]
Towards World Simulator: Crafting Physical Commonsense-Based Benchmark for Video Generation
Fanqing Meng, Jiaqi Liao, Xinyu Tan, Wenqi Shao, Quanfeng Lu, Kaipeng Zhang, Yu Cheng, Dianqi Li, Yu Qiao, and Ping Luo. Towards world simulator: Crafting physical commonsense- based benchmark for video generation.arXiv preprint arXiv:2410.05363, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Transformers are sample-efficient world models
Vincent Micheli, Eloi Alonso, and François Fleuret. Transformers are sample-efficient world models. InInternational Conference on Learning Representations (ICLR), 2023. arXiv:2209.00588
-
[53]
Smoothed particle hydrodynamics.Reports on progress in physics, 68(8):1703– 1759, 2005
Joe J Monaghan. Smoothed particle hydrodynamics.Reports on progress in physics, 68(8):1703– 1759, 2005
2005
-
[54]
Do gener- ative video models understand physical principles? InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 948–958, 2026
Saman Motamed, Laura Culp, Kevin Swersky, Priyank Jaini, and Robert Geirhos. Do gener- ative video models understand physical principles? InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 948–958, 2026
2026
-
[55]
VDAWorld: World Modelling via VLM-Directed Abstraction and Simulation
Felix O’Mahony, Roberto Cipolla, and Ayush Tewari. Vdaworld: World modelling via vlm- directed abstraction and simulation.arXiv preprint arXiv:2512.11061, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Jaideep Pathak, Shashank Subramanian, Peter Harrington, Sanjeev Raja, Ashesh Chattopadhyay, Morteza Mardani, Thorsten Kurth, David Hall, Zongyi Li, Kamyar Azizzadenesheli, Pedram Hassanzadeh, Karthik Kashinath, and Animashree Anandkumar. FourCastNet: A global data- driven high-resolution weather model using adaptive fourier neural operators.arXiv preprint...
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [57]
-
[58]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational physics, 378:686–707, 2019
2019
-
[59]
A VID: Adapting video diffusion models to world models.arXiv preprint arXiv:2410.12822, 2024
Marc Rigter, Tarun Gupta, Agrin Hilmkil, and Chao Ma. A VID: Adapting video diffusion models to world models.arXiv preprint arXiv:2410.12822, 2024
-
[60]
Alvaro Sanchez-Gonzalez, Jonathan Godwin, Tobias Pfaff, Rex Ying, Jure Leskovec, and Peter W. Battaglia. Learning to simulate complex physics with graph networks. InInternational Conference on Machine Learning (ICML), 2020. arXiv:2002.09405
-
[61]
Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy Lillicrap, and David Silver. Mastering Atari, Go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020. arXiv:1911.08265
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[62]
Newton: GPU-accelerated physics simulation for robotics and simulation research, April 2025
The Newton Contributors. Newton: GPU-accelerated physics simulation for robotics and simulation research, April 2025
2025
-
[63]
PhysGaussian: Physics-integrated 3d gaussians for generative dynamics
Tianyi Xie, Zeshun Zong, Yuxing Qiu, Xuan Li, Yutao Feng, Yin Yang, and Chenfanfu Jiang. PhysGaussian: Physics-integrated 3d gaussians for generative dynamics. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2024. arXiv:2311.12198
-
[64]
Chenyu Zhang, Daniil Cherniavskii, Antonios Tragoudaras, Antonios V ozikis, Thijmen Nijdam, Derck WE Prinzhorn, Mark Bodracska, Nicu Sebe, Andrii Zadaianchuk, and Efstratios Gavves. Morpheus: Benchmarking physical reasoning of video generative models with real physical experiments.arXiv preprint arXiv:2504.02918, 2025. 13
-
[65]
Qin Zhang, Peiyu Jing, Hong-Xing Yu, Fangqiang Ding, Fan Nie, Weimin Wang, Yilun Du, James Zou, Jiajun Wu, and Bing Shuai. Physion-eval: Evaluating physical realism in generated video via human reasoning.arXiv preprint arXiv:2603.19607, 2026
-
[66]
Physdreamer: Physics-based interaction with 3d objects via video generation
Tianyuan Zhang, Hong-Xing Yu, Rundi Wu, Brandon Y Feng, Changxi Zheng, Noah Snavely, Jiajun Wu, and William T Freeman. Physdreamer: Physics-based interaction with 3d objects via video generation. InEuropean Conference on Computer Vision, pages 388–406. Springer, 2024
2024
-
[67]
Hierarchical Planning with Latent World Models
Wancong Zhang, Basile Terver, Artem Zholus, Soham Chitnis, Harsh Sutaria, Mido Assran, Randall Balestriero, Amir Bar, Adrien Bardes, Yann LeCun, et al. Hierarchical planning with latent world models.arXiv preprint arXiv:2604.03208, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[68]
Zhenhao Zhou and Dan Negrut. ChronoDreamer: Action-conditioned world model as an online simulator for robotic planning.arXiv preprint arXiv:2512.18619, 2025. 14 A Platforms for Numerical Experimentation In this section, we describe the computational tools and platforms used in our experimental pipeline. These include foundation models (e.g., vision-langua...
-
[69]
In several trials, the model predicts no collision because it states that the target is not in the ball’s path, particularly in the cup and double-jelly scenes
Low-context prompts sometimes produce incorrect physical interpretations of the scene. In several trials, the model predicts no collision because it states that the target is not in the ball’s path, particularly in the cup and double-jelly scenes. Other responses infer incorrect scene geometry or motion entirely, including predicting that objects slide of...
-
[70]
However, the model still does not consistently or precisely predict the realized outcome
High-context prompts isolate the remaining physical prediction errors.When release and collision are explicitly specified, many low-context ambiguities disappear and the responses usually invoke qualitatively relevant effects including rolling motion, momentum transfer, deformation, frictional dissipation, and water sloshing. However, the model still does...
-
[71]
However, the responses still frequently describe tipping, toppling, sliding, and spilling as possible outcomes rather than resolving which event occurs
Counterfactual prompts improve directional reasoning but still produce threshold uncer- tainty.The model usually predicts the correct qualitative trend: lower release height reduces impact energy, honey damps sloshing, high friction suppresses sliding, and gelatin dissipates more energy than rigid blocks. However, the responses still frequently describe t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.