ReScene: Structured Indoor Scene Reconstruction from Multi-View Captures
Pith reviewed 2026-06-29 04:27 UTC · model grok-4.3
The pith
ReScene threads multi-view geometry through view selection and relation fusion to assemble physically consistent indoor scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
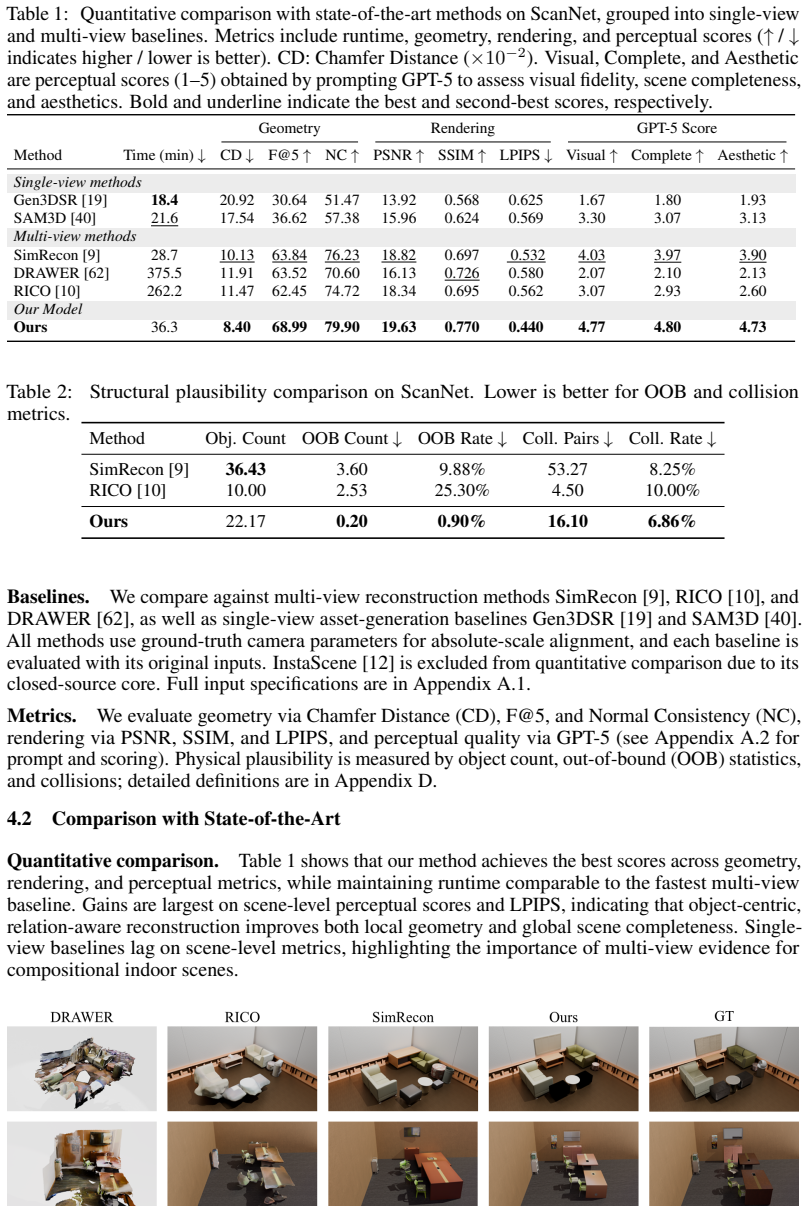
ReScene is a framework for structured indoor scene reconstruction from multi-view captures whose central claim is that cross-view relation fusion and physically plausible scene assembly, not single-object reconstruction, form the core bottleneck. The method consists of HierView, which prioritizes reconstruction views based on semantic consistency and 3D coverage completeness, and Relation-Aware Assembly, which fuses multi-frame relation predictions from a vision-language model with geometric and room-shell priors into a confidence-weighted scene graph. On a set of ScanNet scenes this produces a 17 percent reduction in Chamfer Distance and 26 percent reduction in LPIPS relative to the stronge
What carries the argument
The confidence-weighted scene graph that fuses vision-language model relation predictions with geometric and room-shell priors to enable physically consistent scene assembly.
If this is right
- Reconstructed scenes become directly usable for simulation in Embodied AI without extra physical cleanup steps.
- The same pipeline can generate large embodied visual question answering datasets for training spatial-reasoning models.
- Faster runtime enables reconstruction of substantially more scenes than previous multi-view approaches.
- Explicit object-level structure and inter-object relations improve accuracy on downstream rendering and perceptual tasks.
Where Pith is reading between the lines
- The room-shell prior could be swapped for other structural knowledge to extend the method beyond indoor environments.
- Stronger geometric priors might allow the framework to tolerate noisier vision-language predictions while preserving consistency.
- The approach reduces dependence on specialized capture hardware by leveraging ordinary multi-view image sets.
Load-bearing premise
Multi-frame relation predictions from a vision-language model, when fused with geometric and room-shell priors via a confidence-weighted scene graph, will produce physically consistent assemblies without post-hoc corrections or additional physical simulation validation.
What would settle it
A collection of output scenes that contain clear physical violations such as intersecting objects or unsupported floating objects even when the scene graph reports high confidence on the assembled relations, or an ablation in which removing the relation-fusion step leaves physical-consistency metrics unchanged.
Figures

read the original abstract
Constructing simulation-ready 3D scenes from multi-view captures is a key bottleneck for Embodied Artificial Intelligence, as downstream tasks require object-level structure, explicit inter-object relations, and physical plausibility. Existing approaches either rely on specialized capture hardware, suffer from single-view bias in object reconstruction, or yield layouts that are geometrically reasonable but physically inconsistent. We identify that the problem is not single-object reconstruction but cross-view relation fusion and physically plausible scene assembly. To address this challenge, we present ReScene, a framework that threads multi-view geometry throughout the pipeline as a unifying prior. Our method consists of two main components: HierView prioritizes reconstruction views based on semantic consistency and 3D coverage completeness, replacing the largest-mask heuristic that conflates image occupancy with object coverage; and Relation-Aware Assembly fuses multi-frame relation predictions from a vision-language model with geometric and room-shell priors into a confidence-weighted scene graph, enabling physically consistent scene assembly. ReScene sets a new state of the art across geometry, rendering, and perceptual quality on a set of ScanNet scenes, achieving a 17% reduction in Chamfer Distance and 26% in LPIPS over the strongest prior baseline, while running up to 10x faster than prior multi-view methods. Based on the reconstructed scenes, we also generate an embodied visual question answering dataset, on which fine-tuned Qwen-VL approaches the performance of strong closed-source models on several spatial reasoning tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReScene, a framework for structured indoor scene reconstruction from multi-view captures aimed at producing simulation-ready scenes for Embodied AI. It proposes two components: HierView, which prioritizes views based on semantic consistency and 3D coverage instead of largest-mask heuristics, and Relation-Aware Assembly, which fuses multi-frame VLM relation predictions with geometric and room-shell priors into a confidence-weighted scene graph for physically consistent object assemblies. The work claims SOTA results on ScanNet scenes (17% Chamfer Distance reduction, 26% LPIPS improvement, up to 10x faster than prior multi-view methods) and generates an embodied VQA dataset where fine-tuned Qwen-VL approaches closed-source model performance on spatial tasks.
Significance. If the quantitative gains and physical consistency claims are substantiated, the work would meaningfully advance multi-view scene reconstruction by threading geometry as a prior throughout and leveraging VLM for explicit relations, addressing a bottleneck for downstream Embodied AI tasks. The view prioritization and scene-graph assembly ideas have potential for broader adoption if validated.
major comments (2)
- [Abstract] Abstract: The headline quantitative claims (17% Chamfer Distance reduction, 26% LPIPS improvement, 10x speed-up) are presented without any evaluation protocol, baseline details, dataset splits, error bars, or statistical tests. This directly undermines assessment of the SOTA assertion, which is load-bearing for the paper's contribution.
- [Abstract] Abstract (Relation-Aware Assembly description): The central claim that the method produces physically consistent assemblies via VLM-prior fusion lacks any quantitative validation (e.g., penetration rates, gravity stability, or collision metrics). This is load-bearing because the paper positions physical plausibility as the key differentiator from prior geometrically reasonable but inconsistent layouts.
minor comments (1)
- [Abstract] Abstract: The embodied VQA dataset is mentioned as a contribution but without any details on construction, size, task definitions, or evaluation splits.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that the headline claims require better contextualization and will revise accordingly. Point-by-point responses to the major comments follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline quantitative claims (17% Chamfer Distance reduction, 26% LPIPS improvement, 10x speed-up) are presented without any evaluation protocol, baseline details, dataset splits, error bars, or statistical tests. This directly undermines assessment of the SOTA assertion, which is load-bearing for the paper's contribution.
Authors: The full manuscript details the evaluation protocol, baselines, ScanNet splits, and metrics (including error bars from repeated runs and statistical tests) in Section 4 and the supplementary material. The abstract is length-constrained, but we will revise it to briefly reference the evaluation setting (e.g., "on ScanNet validation scenes") to improve self-containment while preserving conciseness. revision: partial
-
Referee: [Abstract] Abstract (Relation-Aware Assembly description): The central claim that the method produces physically consistent assemblies via VLM-prior fusion lacks any quantitative validation (e.g., penetration rates, gravity stability, or collision metrics). This is load-bearing because the paper positions physical plausibility as the key differentiator from prior geometrically reasonable but inconsistent layouts.
Authors: We agree that the current manuscript lacks direct quantitative physical-consistency metrics such as penetration or collision rates. Physical plausibility is achieved through the geometric and room-shell priors in Relation-Aware Assembly and is supported indirectly by the improved geometry/perceptual metrics and embodied VQA results. We will add explicit quantitative physical validation (e.g., simulation-based collision and stability metrics) to the experiments section in revision. revision: yes
Circularity Check
No circularity: framework is methodological with no derivational reductions
full rationale
The paper describes an engineering pipeline (HierView view prioritization + Relation-Aware Assembly via VLM + geometric priors) evaluated empirically on ScanNet. No equations, parameter-fitting steps, or first-principles derivations appear in the abstract or described structure. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations that reduce the central claims to their own inputs by construction. The physical-consistency claim is an empirical assertion (not a derived theorem), and the reader's note confirms absence of equations. This is the common honest case of a self-contained applied method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AI2-THOR: An Interactive 3D Environment for Visual AI
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, Aniruddha Kembhavi, Abhinav Gupta, and Ali Farhadi. Ai2-thor: An interactive 3d environment for visual ai, 2022. URL https: //arxiv.org/abs/1712.05474
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Habitat: A platform for embodied ai research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, and Dhruv Batra. Habitat: A platform for embodied ai research. InInternational Conference on Computer Vision (ICCV), pages 9339–9347, 2019
2019
-
[3]
Procthor: Large- scale embodied ai using procedural generation, 2022
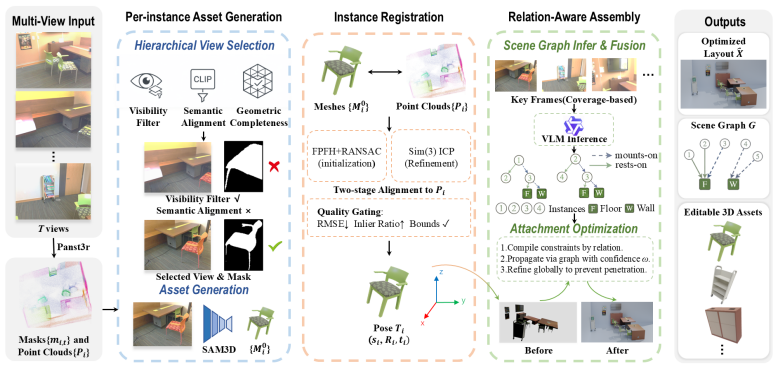
Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Jordi Salvador, Kiana Ehsani, Winson Han, Eric Kolve, Ali Farhadi, Aniruddha Kembhavi, and Roozbeh Mottaghi. Procthor: Large- scale embodied ai using procedural generation, 2022. URL https://arxiv.org/abs/2206. 06994
2022
-
[4]
3D-FRONT: 3d furnished rooms with layouts and semantics
Huan Fu, Bowen Cai, Lin Gao, Ling-Xiao Zhang, Jiaming Wang, Cao Li, Qixun Zeng, Chengyue Sun, Rongfei Jia, Binqiang Zhao, and Hao Zhang. 3D-FRONT: 3d furnished rooms with layouts and semantics. InInternational Conference on Computer Vision (ICCV), pages 10933–10942, 2021
2021
-
[5]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13142–13153, 2023
2023
-
[6]
Metascenes: Towards automated replica creation for real-world 3d scans, 2025
Huangyue Yu, Baoxiong Jia, Yixin Chen, Yandan Yang, Puhao Li, Rongpeng Su, Jiaxin Li, Qing Li, Wei Liang, Song-Chun Zhu, Tengyu Liu, and Siyuan Huang. Metascenes: Towards automated replica creation for real-world 3d scans, 2025. URL https://arxiv.org/abs/ 2505.02388
-
[7]
LiteReality: Graphics-ready 3d scene reconstruction from rgb-d scans, 2025
Zhening Huang, Xiaoyang Wu, Fangcheng Zhong, Hengshuang Zhao, Matthias Nießner, and Joan Lasenby. LiteReality: Graphics-ready 3d scene reconstruction from rgb-d scans, 2025. URLhttps://arxiv.org/abs/2507.02861
-
[8]
Gpt4scene: Understand 3d scenes from videos with vision-language models,
Zhangyang Qi, Zhixiong Zhang, Ye Fang, Jiaqi Wang, and Hengshuang Zhao. GPT4Scene: Understand 3d scenes from videos with vision-language models, 2025. URL https://arxiv. org/abs/2501.01428
-
[9]
SimRecon: Simready compositional scene reconstruction from real videos, 2026
Chong Xia, Kai Zhu, Zizhuo Wang, Fangfu Liu, Zhizheng Zhang, and Yueqi Duan. SimRecon: Simready compositional scene reconstruction from real videos, 2026. URL https://arxiv. org/abs/2603.02133
-
[10]
RICO: Regularizing the unobservable for indoor compositional reconstruction
Zizhang Li, Xiaoyang Lyu, Yuanyuan Ding, Mengmeng Wang, Yiyi Liao, and Yong Liu. RICO: Regularizing the unobservable for indoor compositional reconstruction. InInternational Conference on Computer Vision (ICCV), 2023
2023
-
[11]
Decompositional neural scene reconstruction with generative diffusion prior, 2025
Junfeng Ni, Yu Liu, Ruijie Lu, Zirui Zhou, Song-Chun Zhu, Yixin Chen, and Siyuan Huang. Decompositional neural scene reconstruction with generative diffusion prior, 2025. URL https://arxiv.org/abs/2503.14830
-
[12]
Zesong Yang, Bangbang Yang, Wenqi Dong, Chenxuan Cao, Liyuan Cui, Yuewen Ma, Zhaopeng Cui, and Hujun Bao. Instascene: Towards complete 3d instance decomposition and reconstruc- tion from cluttered scenes, 2025. URLhttps://arxiv.org/abs/2507.08416
-
[13]
Abhishek Das, Samyak Datta, Georgia Gkioxari, Stefan Lee, Devi Parikh, and Dhruv Batra. Embodied question answering, 2017. URLhttps://arxiv.org/abs/1711.11543
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
ScanQA: 3d question answering for spatial scene understanding
Daichi Azuma, Taiki Miyanishi, Shuhei Kurita, and Motoaki Kawanabe. ScanQA: 3d question answering for spatial scene understanding. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 10
2022
-
[15]
SQA3D: Situated question answering in 3d scenes
Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, and Siyuan Huang. SQA3D: Situated question answering in 3d scenes. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[16]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), 2023
2023
-
[17]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view synthesis. In European Conference on Computer Vision (ECCV), pages 405–421, 2020
2020
-
[18]
MonoSDF: Exploring monocular geometric cues for neural implicit surface reconstruction
Zehao Yu, Songyou Peng, Michael Niemeyer, Torsten Sattler, and Andreas Geiger. MonoSDF: Exploring monocular geometric cues for neural implicit surface reconstruction. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[19]
Generalizable 3d scene reconstruction via divide and conquer from a single view
Andreea Ardelean, Mert Özer, and Bernhard Egger. Generalizable 3d scene reconstruction via divide and conquer from a single view. InInternational Conference on 3D Vision (3DV), 2025
2025
-
[20]
Midi: Multi-instance diffusion for single image to 3d scene generation, 2025
Zehuan Huang, Yuan-Chen Guo, Xingqiao An, Yunhan Yang, Yangguang Li, Zi-Xin Zou, Ding Liang, Xihui Liu, Yan-Pei Cao, and Lu Sheng. Midi: Multi-instance diffusion for single image to 3d scene generation, 2025. URLhttps://arxiv.org/abs/2412.03558
-
[21]
Scenegen: Single-image 3d scene generation in one feedforward pass, 2025
Yanxu Meng, Haoning Wu, Ya Zhang, and Weidi Xie. Scenegen: Single-image 3d scene generation in one feedforward pass, 2025. URLhttps://arxiv.org/abs/2508.15769
-
[22]
Cast: Component-aligned 3d scene reconstruction from an rgb image.ACM Trans
Kaixin Yao, Longwen Zhang, Xinhao Yan, Yan Zeng, Qixuan Zhang, Lan Xu, Wei Yang, Jiayuan Gu, and Jingyi Yu. Cast: Component-aligned 3d scene reconstruction from an rgb image.ACM Trans. Graph., 44(4), July 2025. ISSN 0730-0301. doi: 10.1145/3730841. URL https://doi.org/10.1145/3730841
-
[23]
DeepSDF: Learning continuous signed distance functions for shape representation
Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove. DeepSDF: Learning continuous signed distance functions for shape representation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[24]
Barron, and Ben Mildenhall
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. DreamFusion: Text-to-3d using 2d diffusion. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[25]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[26]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations (ICLR), 2021
2021
-
[27]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[28]
ShapeNet: An Information-Rich 3D Model Repository
Angel X. Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, and Fisher Yu. ShapeNet: An information-rich 3d model repository.arXiv preprint arXiv:1512.03012, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[29]
Objaverse-XL: A universe of 10m+ 3d objects
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Ujval Kusupati, Alan Fan, Christian Laforte, Vikram V oleti, Samir Yitzhak Gadre, Eli VanderBilt, Aniruddha Kembhavi, Carl V ondrick, Georgia Gkioxari, Kiana Ehsani, Ludwig Schmidt, and Ali Farhadi. Objaverse-XL: A universe of 10m+ 3d objects. InAdvances in Neural Information Processin...
2023
-
[30]
3D-FUTURE: 3d furniture shape with textures.Interna- tional Journal of Computer Vision, 2021
Huan Fu, Bowen Cai, Lin Gao, Ling-Xiao Zhang, Cao Li, Qixun Zeng, Chengyue Sun, Rongfei Jia, Binqiang Zhao, and Hao Zhang. 3D-FUTURE: 3d furniture shape with textures.Interna- tional Journal of Computer Vision, 2021
2021
-
[31]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InInternational Conference on Computer Vision (ICCV), 2023. 11
2023
-
[32]
Clay: A controllable large-scale generative model for creating high-quality 3d assets, 2024
Longwen Zhang, Ziyu Wang, Qixuan Zhang, Qiwei Qiu, Anqi Pang, Haoran Jiang, Wei Yang, Lan Xu, and Jingyi Yu. Clay: A controllable large-scale generative model for creating high-quality 3d assets, 2024. URLhttps://arxiv.org/abs/2406.13897
-
[33]
TripoSG: High-Fidelity 3D Shape Synthesis using Large-Scale Rectified Flow Models
Yangguang Li, Zi-Xin Zou, Zexiang Liu, Dehu Wang, Yuan Liang, Zhipeng Yu, Xingchao Liu, Yuan-Chen Guo, Ding Liang, Wanli Ouyang, and Yan-Pei Cao. Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models, 2025. URL https://arxiv.org/ abs/2502.06608
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Direct3d: Scalable image-to-3d generation via 3d latent diffusion transformer, 2024
Shuang Wu, Youtian Lin, Feihu Zhang, Yifei Zeng, Jingxi Xu, Philip Torr, Xun Cao, and Yao Yao. Direct3d: Scalable image-to-3d generation via 3d latent diffusion transformer, 2024. URL https://arxiv.org/abs/2405.14832
-
[35]
Hunyuan3d 1.0: A unified framework for text-to-3d and image-to-3d generation, 2025
Xianghui Yang, Huiwen Shi, Bowen Zhang, Fan Yang, Jiacheng Wang, Hongxu Zhao, Xinhai Liu, Xinzhou Wang, Qingxiang Lin, Jiaao Yu, Lifu Wang, Jing Xu, Zebin He, Zhuo Chen, Sicong Liu, Junta Wu, Yihang Lian, Shaoxiong Yang, Yuhong Liu, Yong Yang, Di Wang, Jie Jiang, and Chunchao Guo. Hunyuan3d 1.0: A unified framework for text-to-3d and image-to-3d generatio...
-
[36]
Structured 3d latents for scalable and versatile 3d generation,
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d generation,
-
[37]
URLhttps://arxiv.org/abs/2412.01506
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Weiyu Li, Jiarui Liu, Hongyu Yan, Rui Chen, Yixun Liang, Xuelin Chen, Ping Tan, and Xiaoxiao Long. Craftsman3d: High-fidelity mesh generation with 3d native generation and interactive geometry refiner, 2025. URLhttps://arxiv.org/abs/2405.14979
-
[39]
Zibo Zhao, Wen Liu, Xin Chen, Xianfang Zeng, Rui Wang, Pei Cheng, Bin Fu, Tao Chen, Gang Yu, and Shenghua Gao. Michelangelo: Conditional 3d shape generation based on shape-image- text aligned latent representation, 2023. URLhttps://arxiv.org/abs/2306.17115
-
[40]
Hi3dgen: High-fidelity 3d geometry generation from images via normal bridging, 2025
Chongjie Ye, Yushuang Wu, Ziteng Lu, Jiahao Chang, Xiaoyang Guo, Jiaqing Zhou, Hao Zhao, and Xiaoguang Han. Hi3dgen: High-fidelity 3d geometry generation from images via normal bridging, 2025. URLhttps://arxiv.org/abs/2503.22236
-
[41]
SAM 3D: 3Dfy Anything in Images
SAM 3D Team, Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, Aohan Lin, Jiawei Liu, Ziqi Ma, Anushka Sagar, Bowen Song, Xiaodong Wang, Jianing Yang, Bowen Zhang, Piotr Dollár, Georgia Gkioxari, Matt Feiszli, and Jitendra Malik. SAM 3D: 3dfy anything in images, 2025. URLht...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner
Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. ScanNet: Richly-annotated 3d reconstructions of indoor scenes. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
2017
-
[43]
Matterport3D: Learning from RGB-D data in indoor environments
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Nießner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3D: Learning from RGB-D data in indoor environments. InInternational Conference on 3D Vision (3DV), 2017
2017
-
[44]
ARKitScenes: A diverse real-world dataset for 3d indoor scene understanding using mobile RGB-D data
Gilad Baruch, Zhuoyuan Chen, Afshin Dehghan, Tal Dimry, Yuri Feigin, Peter Fu, Thomas Gebauer, Brandon Joffe, Daniel Kurz, Arik Schwartz, and Elad Shulman. ARKitScenes: A diverse real-world dataset for 3d indoor scene understanding using mobile RGB-D data. In Advances in Neural Information Processing Systems Datasets and Benchmarks Track, 2021
2021
-
[45]
ScanNet++: A high-fidelity dataset of 3d indoor scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. ScanNet++: A high-fidelity dataset of 3d indoor scenes. InInternational Conference on Computer Vision (ICCV), 2023
2023
-
[46]
Julian Straub, Thomas Whelan, Lingni Ma, Yufan Chen, Erik Wijmans, Simon Green, Jakob J. Engel, Raul Mur-Artal, Carl Ren, Shobhit Verma, Anton Clarkson, Ming Yan, Brian Budge, Yuan Yan, Xiaqing Pan, June Yon, Yuyang Zou, Kimberly Leon, Nigel Carter, Jesus Briales, Tyler Gillingham, Elias Mueggler, Luis Pesqueira, Manolis Savva, Dhruv Batra, Hauke Strasdat...
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[47]
SceneNN: A scene meshes dataset with annotations
Binh-Son Hua, Quang-Hieu Pham, Duc Thanh Nguyen, Minh-Khoi Tran, Lap-Fai Yu, and Sai-Kit Yeung. SceneNN: A scene meshes dataset with annotations. InInternational Conference on 3D Vision (3DV), 2016
2016
-
[48]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model, 2024. URL https://arxiv. org/abs/...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action,
Dhruv Shah, Blazej Osinski, Brian Ichter, and Sergey Levine. Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action, 2022. URL https://arxiv.org/ abs/2207.04429
-
[50]
Karen Liu, Silvio Savarese, Hyowon Gweon, Jiajun Wu, and Li Fei-Fei
Sanjana Srivastava, Chengshu Li, Michael Lingelbach, Roberto Martín-Martín, Fei Xia, Kent Vainio, Zheng Lian, Cem Gokmen, Shyamal Buch, C. Karen Liu, Silvio Savarese, Hyowon Gweon, Jiajun Wu, and Li Fei-Fei. Behavior: Benchmark for everyday household activities in virtual, interactive, and ecological environments, 2021. URL https://arxiv.org/abs/ 2108.03332
-
[51]
arXiv preprint arXiv:2310.13724 (2023) 3
Xavier Puig, Eric Undersander, Andrew Szot, Marc-Alexandre Cote, Tsung-Yen Yang, Rus- lan Partsey, Rutav Desai, Alexander Clegg, Michal Hlavac, So Yeon Min, Viktor V ondrus, Theophile Gervet, Vincent-Pierre Berges, John Turner, Oleksandr Maksymets, Zsolt Kira, Mri- nal Kalakrishnan, Jitendra Malik, Devendra Singh Chaplot, Unnat Jain, Dhruv Batra, Akshara ...
-
[52]
Behavior vision suite: Customizable dataset generation via simulation, 2024
Yunhao Ge, Yihe Tang, Jiashu Xu, Cem Gokmen, Chengshu Li, Wensi Ai, Benjamin Jose Martinez, Arman Aydin, Mona Anvari, Ayush K Chakravarthy, Hong-Xing Yu, Josiah Wong, Sanjana Srivastava, Sharon Lee, Shengxin Zha, Laurent Itti, Yunzhu Li, Roberto Martín-Martín, Miao Liu, Pengchuan Zhang, Ruohan Zhang, Li Fei-Fei, and Jiajun Wu. Behavior vision suite: Custo...
2024
-
[53]
ATISS: Autoregressive transformers for indoor scene synthesis
Despoina Paschalidou, Amlan Kar, Maria Shugrina, Karsten Kreis, Andreas Geiger, and Sanja Fidler. ATISS: Autoregressive transformers for indoor scene synthesis. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[54]
Holodeck: Language guided generation of 3d embodied ai environments, 2024
Yue Yang, Fan-Yun Sun, Luca Weihs, Eli VanderBilt, Alvaro Herrasti, Winson Han, Jiajun Wu, Nick Haber, Ranjay Krishna, Lingjie Liu, Chris Callison-Burch, Mark Yatskar, Aniruddha Kembhavi, and Christopher Clark. Holodeck: Language guided generation of 3d embodied ai environments, 2024. URLhttps://arxiv.org/abs/2312.09067
-
[55]
DiffuScene: Denoising diffusion models for generative indoor scene synthesis
Jiapeng Tang, Yinyu Nie, Lev Markhasin, Angela Dai, Justus Thies, and Matthias Nießner. DiffuScene: Denoising diffusion models for generative indoor scene synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[56]
Panst3r: Multi-view consistent panoptic segmentation, 2025
Lojze Zust, Yohann Cabon, Juliette Marrie, Leonid Antsfeld, Boris Chidlovskii, Jerome Revaud, and Gabriela Csurka. Panst3r: Multi-view consistent panoptic segmentation, 2025. URL https://arxiv.org/abs/2506.21348
-
[57]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInterna- tional Conference on Machine Learning (ICML), 2021
2021
-
[58]
Fast point feature histograms (FPFH) for 3d registration
Radu Bogdan Rusu, Nico Blodow, and Michael Beetz. Fast point feature histograms (FPFH) for 3d registration. InIEEE International Conference on Robotics and Automation (ICRA), 2009
2009
-
[59]
Least-squares estimation of transformation parameters between two point patterns.IEEE Transactions on Pattern Analysis and Machine Intelligence, 13(4):376–380, 1991
Shinji Umeyama. Least-squares estimation of transformation parameters between two point patterns.IEEE Transactions on Pattern Analysis and Machine Intelligence, 13(4):376–380, 1991. 13
1991
-
[60]
Learning 3d semantic scene graphs from 3d indoor reconstructions
Johanna Wald, Helisa Dhamo, Nassir Navab, and Federico Tombari. Learning 3d semantic scene graphs from 3d indoor reconstructions. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[61]
Hydra: A real-time spatial perception system for 3d scene graph construction and optimization
Nathan Hughes, Yun Chang, and Luca Carlone. Hydra: A real-time spatial perception system for 3d scene graph construction and optimization. InRobotics: Science and Systems (RSS), 2022
2022
-
[62]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
visual_fidelity
Hongchi Xia, Entong Su, Marius Memmel, Arhan Jain, Raymond Yu, Numfor Mbiziwo-Tiapo, Ali Farhadi, Abhishek Gupta, Shenlong Wang, and Wei-Chiu Ma. DRAWER: Digital recon- struction and articulation with environment realism. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21771–21782, 2025. A Evaluation Protocol A.1 Baseline In...
2025
-
[64]
Panoptic multi-view reconstruction.We run PanSt3R to obtain camera-aware multi-view geometry, instance masks, per-instance labels, and semantic point clouds in a shared world coordinate frame
-
[65]
HierView selection.For each instance, we select one reconstruction view using the visibility, semantic, and 3D-completeness filters described in Sec. 3.2
-
[66]
Single-view asset generation.The selected image and mask are passed to SAM3D-Objects to reconstruct an initial per-instance mesh
-
[67]
Instance registration.Each generated mesh is aligned to its corresponding semantic point cloud using bounded Sim(3) registration
-
[68]
Scene graph construction.We select key frames by greedy 3D coverage, render ID-overlaid images, infer per-frame relations with a VLM, and merge them into a global scene graph
-
[69]
Attachment and refinement.We compile relation edges into geometric constraints, run the attachment solver, optionally run a floor-only branch for dual attachment, and apply staged post-refinement and depenetration. All stages share the same instance IDs, so the selected view, generated mesh, registration target, scene graph node, and final attachment tran...
-
[70]
Build the candidate view set from frames where the instance has a non-empty mask
-
[71]
Remove candidates with mask area belowa min or bounding-box area ratio belowb min. 17
-
[72]
Encode the masked crop and the category text with CLIP, then keep views whose semantic score is above the threshold or whose semantic rank is sufficiently high
-
[73]
Project a capped set of instance points into each remaining view and compute the fraction landing inside the mask
-
[74]
objects": [ {
Select the view with the highest 3D-to-2D completeness score. If a stage removes all candidates, the implementation falls back to the best candidate from the previous stage rather than dropping the instance immediately. Table A2: Default HierView hyperparameters. Parameter Value CLIP backend/model ViT-B/32 Semantic probability thresholdτ s 0.12 Semantic r...
-
[75]
Floor snap: snap floor-supported objects to the floor plane and project footprints back into the floor boundary if needed
-
[76]
Wall resolution: resolve the canonical wall root to a concrete wall plane by distance and orientation agreement
-
[77]
Wall attachment: align wall-mounted objects to the selected wall plane while preserving lateral order along the wall
-
[78]
Object support: project child contact surfaces onto feasible support faces of parent objects
-
[79]
Near-wall snap: optionally snap large furniture near walls when the scene graph and geometry support it
-
[80]
Outside repair: move objects whose footprints leave the room boundary back toward feasible interior positions
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.