Recognition: unknown
ReplicateAnyScene: Zero-Shot Video-to-3D Composition via Textual-Visual-Spatial Alignment
Pith reviewed 2026-05-10 15:33 UTC · model grok-4.3
The pith
A five-stage cascade extracts and aligns textual, visual, and spatial priors from vision models to convert casual videos into coherent 3D scenes automatically.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ReplicateAnyScene is a zero-shot framework that transforms casually captured videos into compositional 3D scenes through a five-stage cascade. The cascade extracts generic priors from vision foundation models along textual, visual, and spatial dimensions, then structurally aligns and grounds those priors into physically plausible 3D representations while preserving semantic coherence.
What carries the argument
The five-stage cascade that extracts textual, visual, and spatial priors from foundation models and aligns them into structured 3D representations.
If this is right
- Removes the need for manual object prompting or auxiliary visual inputs in video-to-3D pipelines.
- Produces scenes that maintain semantic coherence and physical plausibility across diverse casual videos.
- Extends beyond the simple scenes that training-biased methods can handle.
- Provides the C3DR benchmark for systematic multi-aspect evaluation of compositional 3D reconstruction.
Where Pith is reading between the lines
- If the alignment succeeds across modalities, similar cascades could be applied to other video-to-geometry tasks such as dynamic scene editing.
- The method implicitly suggests that foundation-model priors are already rich enough for 3D grounding, reducing the need for large 3D-specific training sets.
- Deployment in embodied AI would become feasible once the cascade handles longer videos or changing lighting without drift.
Load-bearing premise
Off-the-shelf vision foundation models already supply accurate and mutually consistent textual, visual, and spatial priors that a fixed five-stage cascade can turn into physically plausible 3D scenes without any task-specific fine-tuning.
What would settle it
A test set of casual videos in which the foundation-model priors disagree on object boundaries or spatial relations, followed by measurement of whether the output 3D scenes show clear physical implausibility or semantic errors.
Figures



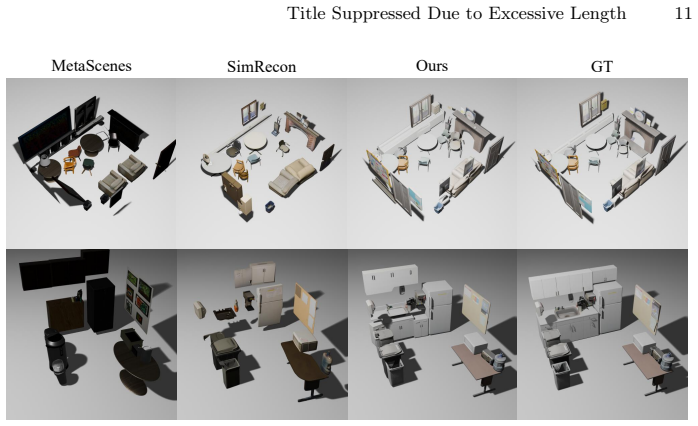

read the original abstract
Humans exhibit an innate capacity to rapidly perceive and segment objects from video observations, and even mentally assemble them into structured 3D scenes. Replicating such capability, termed compositional 3D reconstruction, is pivotal for the advancement of Spatial Intelligence and Embodied AI. However, existing methods struggle to achieve practical deployment due to the insufficient integration of cross-modal information, leaving them dependent on manual object prompting, reliant on auxiliary visual inputs, and restricted to overly simplistic scenes by training biases. To address these limitations, we propose ReplicateAnyScene, a framework capable of fully automated and zero-shot transformation of casually captured videos into compositional 3D scenes. Specifically, our pipeline incorporates a five-stage cascade to extract and structurally align generic priors from vision foundation models across textual, visual, and spatial dimensions, grounding them into structured 3D representations and ensuring semantic coherence and physical plausibility of the constructed scenes. To facilitate a more comprehensive evaluation of this task, we further introduce the C3DR benchmark to assess reconstruction quality from diverse aspects. Extensive experiments demonstrate the superiority of our method over existing baselines in generating high-quality compositional 3D scenes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ReplicateAnyScene, a zero-shot framework for transforming casually captured videos into compositional 3D scenes. It employs a five-stage cascade to extract and structurally align generic priors from vision foundation models across textual, visual, and spatial dimensions, grounding them into structured 3D representations while claiming to ensure semantic coherence and physical plausibility without manual prompting, auxiliary inputs, or task-specific fine-tuning. The work also introduces the C3DR benchmark for multi-aspect evaluation and reports superiority over baselines in experiments.
Significance. If the cascade reliably reconciles potentially inconsistent priors from off-the-shelf models (e.g., CLIP-style text, SAM-style segmentation, monocular depth/pose) into physically plausible 3D scenes, the result would advance automated compositional reconstruction for embodied AI and spatial intelligence. The introduction of the C3DR benchmark is a clear positive contribution that enables more rigorous future comparisons. The zero-shot, fully automated design addresses practical deployment barriers noted in prior work.
major comments (2)
- [Abstract] Abstract: The central claim that the five-stage cascade 'extract[s] and structurally align[s] generic priors ... grounding them into structured 3D representations and ensuring semantic coherence and physical plausibility' is load-bearing, yet the abstract provides no description of the stages, alignment procedure, or mechanism for detecting/reconciling conflicts (e.g., segmentation boundaries disagreeing with depth edges or captions omitting spatial relations). Without such details or ablations, it is impossible to verify that a fixed non-learned cascade suffices for complex casual videos.
- [Abstract] Abstract (and implied §4 Experiments): The assertion of 'superiority ... in generating high-quality compositional 3D scenes' and 'extensive experiments' is not supported by any referenced quantitative metrics, ablation studies, error analysis, or tables in the provided description. This undermines assessment of whether the pipeline actually achieves the claimed physical plausibility, especially given the weakest assumption that foundation-model priors are already mutually consistent.
minor comments (1)
- [Abstract] The abstract uses 'ReplicateAnyScene' and 'C3DR benchmark' without initial definition or expansion; clarify on first use.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address the major comments point by point below, agreeing that the abstract can be strengthened for clarity while noting that the full manuscript already contains the requested technical details and experimental support.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the five-stage cascade 'extract[s] and structurally align[s] generic priors ... grounding them into structured 3D representations and ensuring semantic coherence and physical plausibility' is load-bearing, yet the abstract provides no description of the stages, alignment procedure, or mechanism for detecting/reconciling conflicts (e.g., segmentation boundaries disagreeing with depth edges or captions omitting spatial relations). Without such details or ablations, it is impossible to verify that a fixed non-learned cascade suffices for complex casual videos.
Authors: We agree that the abstract's brevity limits immediate visibility into the pipeline. The full manuscript (Section 3) details the five-stage cascade: (1) textual prior extraction via vision-language models, (2) visual segmentation and feature alignment, (3) spatial prior estimation from monocular depth and pose, (4) cross-dimensional structural alignment using geometric and semantic constraints, and (5) 3D grounding with conflict resolution (e.g., depth edges override inconsistent segmentation boundaries, and spatial relations from captions guide object layout). Section 4.3 provides ablations confirming each stage's role in reconciling inconsistencies without learned components. We will revise the abstract to include a concise outline of the stages and reconciliation approach. revision: yes
-
Referee: [Abstract] Abstract (and implied §4 Experiments): The assertion of 'superiority ... in generating high-quality compositional 3D scenes' and 'extensive experiments' is not supported by any referenced quantitative metrics, ablation studies, error analysis, or tables in the provided description. This undermines assessment of whether the pipeline actually achieves the claimed physical plausibility, especially given the weakest assumption that foundation-model priors are already mutually consistent.
Authors: The abstract summarizes results at a high level, but we concur that explicit metrics would better substantiate the claims. The full manuscript (Section 4) reports quantitative results on the C3DR benchmark, including metrics for semantic coherence, geometric accuracy, and physical plausibility, with ablations, error analysis, and comparisons to baselines demonstrating superiority and the effectiveness of the alignment process in handling inconsistent priors. We will revise the abstract to reference key quantitative outcomes and note that the cascade explicitly mitigates prior inconsistencies rather than assuming consistency. revision: yes
Circularity Check
No circularity: engineering pipeline without self-referential derivations
full rationale
The paper describes a five-stage cascade that extracts and aligns priors from existing vision foundation models (textual, visual, spatial) to produce compositional 3D scenes from video. No equations, fitted parameters, or uniqueness theorems are presented that reduce outputs to inputs by construction. Claims of semantic coherence and physical plausibility rest on the empirical behavior of off-the-shelf models plus a fixed cascade, evaluated on a newly introduced benchmark; these are not tautological or self-citation-dependent. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision foundation models supply reliable generic priors across textual, visual, and spatial dimensions that can be structurally aligned without task-specific training.
Reference graph
Works this paper leans on
-
[1]
Gpt-4v(ision) system card (2023),https://api.semanticscholar.org/CorpusID: 263218031
2023
-
[2]
In: 2025 International Conference on 3D Vision (3DV)
Ardelean, A., Özer, M., Egger, B.: Gen3dsr: Generalizable 3d scene reconstruction via divide and conquer from a single view. In: 2025 International Conference on 3D Vision (3DV). pp. 616–626. IEEE (2025)
2025
-
[3]
In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition
Avetisyan, A., Dahnert, M., Dai, A., Savva, M., Chang, A.X., Nießner, M.: Scan2cad: Learning cad model alignment in rgb-d scans. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition. pp. 2614–2623 (2019)
2019
-
[4]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
ARKitScenes: A Diverse Real-World Dataset For 3D Indoor Scene Understanding Using Mobile RGB-D Data
Baruch, G., Chen, Z., Dehghan, A., Dimry, T., Feigin, Y., Fu, P., Gebauer, T., Joffe, B., Kurz, D., Schwartz, A., et al.: Arkitscenes: A diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data. arXiv preprint arXiv:2111.08897 (2021)
work page internal anchor Pith review arXiv 2021
-
[6]
In: Sensor fusion IV: control paradigms and data structures
Besl, P.J., McKay, N.D.: Method for registration of 3-d shapes. In: Sensor fusion IV: control paradigms and data structures. vol. 1611, pp. 586–606. Spie (1992)
1992
-
[7]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala,K.V.,Khedr,H.,Huang,A.,etal.:Sam3:Segmentanythingwithconcepts. arXiv preprint arXiv:2511.16719 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Matterport3D: Learning from RGB-D Data in Indoor Environments
Chang, A., Dai, A., Funkhouser, T., Halber, M., Niessner, M., Savva, M., Song, S., Zeng, A., Zhang, Y.: Matterport3d: Learning from rgb-d data in indoor envi- ronments. arXiv preprint arXiv:1709.06158 (2017)
work page Pith review arXiv 2017
-
[9]
ShapeNet: An Information-Rich 3D Model Repository
Chang, A.X., Funkhouser, T., Guibas, L., Hanrahan, P., Huang, Q., Li, Z., Savarese, S., Savva, M., Song, S., Su, H., et al.: Shapenet: An information-rich 3d model repository. arXiv preprint arXiv:1512.03012 (2015)
work page internal anchor Pith review arXiv 2015
-
[10]
SAM 3D: 3Dfy Anything in Images
Chen, X., Chu, F.J., Gleize, P., Liang, K.J., Sax, A., Tang, H., Wang, W., Guo, M., Hardin, T., Li, X., et al.: Sam 3d: 3dfy anything in images. arXiv preprint arXiv:2511.16624 (2025)
work page internal anchor Pith review arXiv 2025
-
[11]
Abot-n0: Technical report on the vla foundation model for versatile embodied navigation
Chu, Z., Xie, S., Wu, X., Shen, Y., Luo, M., Wang, Z., Liu, F., Leng, X., Hu, J., Yin, M., et al.: Abot-n0: Technical report on the vla foundation model for versatile embodied navigation. arXiv preprint arXiv:2602.11598 (2026)
-
[12]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Dai,A.,Chang,A.X.,Savva,M.,Halber,M.,Funkhouser,T.,Nießner,M.:Scannet: Richly-annotated 3d reconstructions of indoor scenes. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5828–5839 (2017)
2017
-
[13]
Advances in Neural Information Processing Systems36, 35799–35813 (2023)
Deitke, M., Liu, R., Wallingford, M., Ngo, H., Michel, O., Kusupati, A., Fan, A., Laforte, C., Voleti, V., Gadre, S.Y., et al.: Objaverse-xl: A universe of 10m+ 3d objects. Advances in Neural Information Processing Systems36, 35799–35813 (2023)
2023
-
[14]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., Schmidt, L., Ehsani, K., Kembhavi, A., Farhadi, A.: Objaverse: A universe of annotated 3d objects. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13142–13153 (2023)
2023
-
[15]
Advances in Neural Information Processing Systems 35, 5982–5994 (2022) 16 Authors Suppressed Due to Excessive Length
Deitke, M., VanderBilt, E., Herrasti, A., Weihs, L., Ehsani, K., Salvador, J., Han, W., Kolve, E., Kembhavi, A., Mottaghi, R.: Procthor: Large-scale embodied ai using procedural generation. Advances in Neural Information Processing Systems 35, 5982–5994 (2022) 16 Authors Suppressed Due to Excessive Length
2022
-
[16]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Fu, H., Cai, B., Gao, L., Zhang, L.X., Wang, J., Li, C., Zeng, Q., Sun, C., Jia, R., Zhao, B., et al.: 3d-front: 3d furnished rooms with layouts and semantics. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10933–10942 (2021)
2021
-
[17]
International Journal of Computer Vision129(12), 3313–3337 (2021)
Fu, H., Jia, R., Gao, L., Gong, M., Zhao, B., Maybank, S., Tao, D.: 3d-future: 3d furniture shape with texture. International Journal of Computer Vision129(12), 3313–3337 (2021)
2021
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ge, Y., Tang, Y., Xu, J., Gokmen, C., Li, C., Ai, W., Martinez, B.J., Aydin, A., Anvari, M., Chakravarthy, A.K., et al.: Behavior vision suite: Customizable dataset generation via simulation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22401–22412 (2024)
2024
-
[19]
google/(2026), accessed: 2026-03-05
Google DeepMind: Nano banana 2 (gemini 3.1 flash image).https://gemini. google/(2026), accessed: 2026-03-05
2026
-
[20]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[21]
In: 2016 fourth international conference on 3D vision (3DV)
Hua, B.S., Pham, Q.H., Nguyen, D.T., Tran, M.K., Yu, L.F., Yeung, S.K.: Scenenn: A scene meshes dataset with annotations. In: 2016 fourth international conference on 3D vision (3DV). pp. 92–101. Ieee (2016)
2016
-
[22]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., Guo, Y.C., An, X., Yang, Y., Li, Y., Zou, Z.X., Liang, D., Liu, X., Cao, Y.P., Sheng, L.: Midi: Multi-instance diffusion for single image to 3d scene generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 23646–23657 (2025)
2025
-
[23]
Mv-adapter: Multi-view consistent image generation made easy.arXiv preprint arXiv:2412.03632, 2024
Huang, Z., Guo, Y., Wang, H., Yi, R., Ma, L., Cao, Y.P., Sheng, L.: Mv- adapter: Multi-view consistent image generation made easy. arXiv preprint arXiv:2412.03632 (2024)
-
[24]
In: Proceedings of the IEEE/CVF international conference on computer vision
Ke, J., Wang, Q., Wang, Y., Milanfar, P., Yang, F.: Musiq: Multi-scale image quality transformer. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5148–5157 (2021)
2021
-
[25]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G., et al.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023)
2023
-
[26]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., et al.: Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Auto-Encoding Variational Bayes
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[28]
Leroy, V., Cabon, Y., Revaud, J.: Grounding image matching in 3d with mast3r (2024)
2024
-
[29]
Li, W., Liu, J., Yan, H., Chen, R., Liang, Y., Chen, X., Tan, P., Long, X.: Crafts- man3d: High-fidelity mesh generation with 3d native generation and interactive geometry refiner (2024)
2024
-
[30]
arXiv preprint arXiv:2502.06608 (2025)
Li, Y., Zou, Z.X., Liu, Z., Wang, D., Liang, Y., Yu, Z., Liu, X., Guo, Y.C., Liang, D., Ouyang, W., et al.: Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models. arXiv preprint arXiv:2502.06608 (2025)
-
[31]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Liu, Y., Lin, C., Zeng, Z., Long, X., Liu, L., Komura, T., Wang, W.: Syncdreamer: Generating multiview-consistent images from a single-view image. arXiv preprint arXiv:2309.03453 (2023)
-
[33]
Wonder3d: Sin- gle image to 3d using cross-domain diffusion.arXiv preprint arXiv:2310.15008, 2023
Long, X., Guo, Y.C., Lin, C., Liu, Y., Dou, Z., Liu, L., Ma, Y., Zhang, S.H., Habermann, M., Theobalt, C., et al.: Wonder3d: Single image to 3d using cross- domain diffusion. arXiv preprint arXiv:2310.15008 (2023) Title Suppressed Due to Excessive Length 17
-
[34]
Lu, H., Liu, W., Zhang, B., Wang, B., Dong, K., Liu, B., Sun, J., Ren, T., Li, Z., Yang, H., Sun, Y., Deng, C., Xu, H., Xie, Z., Ruan, C.: Deepseek-vl: Towards real-world vision-language understanding (2024)
2024
-
[35]
arXiv preprint arXiv:2508.15769 (2025)
Meng, Y., Wu, H., Zhang, Y., Xie, W.: Scenegen: Single-image 3d scene generation in one feedforward pass. arXiv preprint arXiv:2508.15769 (2025)
-
[36]
Commu- nications of the ACM65(1), 99–106 (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM65(1), 99–106 (2021)
2021
-
[37]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ni, J., Liu, Y., Lu, R., Zhou, Z., Zhu, S.C., Chen, Y., Huang, S.: Decompositional neural scene reconstruction with generative diffusion prior. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 6022–6033 (2025)
2025
-
[38]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Park,J.J.,Florence,P.,Straub,J.,Newcombe,R.,Lovegrove,S.:Deepsdf:Learning continuous signed distance functions for shape representation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 165– 174 (2019)
2019
-
[39]
Advances in neural infor- mation processing systems34, 12013–12026 (2021)
Paschalidou, D., Kar, A., Shugrina, M., Kreis, K., Geiger, A., Fidler, S.: Atiss: Autoregressive transformers for indoor scene synthesis. Advances in neural infor- mation processing systems34, 12013–12026 (2021)
2021
-
[40]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[41]
DreamFusion: Text-to-3D using 2D Diffusion
Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988 (2022)
work page internal anchor Pith review arXiv 2022
-
[42]
arXiv preprint arXiv:2310.13724 (2023) 14
Puig, X., Undersander, E., Szot, A., Cote, M.D., Yang, T.Y., Partsey, R., Desai, R., Clegg, A.W., Hlavac, M., Min, S.Y., et al.: Habitat 3.0: A co-habitat for humans, avatars and robots. arXiv preprint arXiv:2310.13724 (2023)
-
[43]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[44]
In: Conference on robot learning
Shah, D., Osiński, B., Levine, S., et al.: Lm-nav: Robotic navigation with large pre- trained models of language, vision, and action. In: Conference on robot learning. pp. 492–504. pmlr (2023)
2023
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Shih, M.L., Ma, W.C., Boyice, L., Holynski, A., Cole, F., Curless, B., Kontkanen, J.: Extranerf: Visibility-aware view extrapolation of neural radiance fields with dif- fusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20385–20395 (2024)
2024
-
[46]
Denoising Diffusion Implicit Models
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[47]
In: Conference on robot learning
Srivastava, S., Li, C., Lingelbach, M., Martín-Martín, R., Xia, F., Vainio, K.E., Lian, Z., Gokmen, C., Buch, S., Liu, K., et al.: Behavior: Benchmark for every- day household activities in virtual, interactive, and ecological environments. In: Conference on robot learning. pp. 477–490. PMLR (2022)
2022
-
[48]
The Replica Dataset: A Digital Replica of Indoor Spaces
Straub, J., Whelan, T., Ma, L., Chen, Y., Wijmans, E., Green, S., Engel, J.J., Mur-Artal, R., Ren, C., Verma, S., et al.: The replica dataset: A digital replica of indoor spaces. arXiv preprint arXiv:1906.05797 (2019)
work page internal anchor Pith review arXiv 1906
-
[49]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Tang, J., Nie, Y., Markhasin, L., Dai, A., Thies, J., Nießner, M.: Diffuscene: De- noising diffusion models for generative indoor scene synthesis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20507– 20518 (2024)
2024
-
[50]
Tang, J., Chen, Z., Chen, X., Wang, T., Zeng, G., Liu, Z.: Lgm: Large multi- view gaussian model for high-resolution 3d content creation. arXiv preprint arXiv:2402.05054 (2024) 18 Authors Suppressed Due to Excessive Length
-
[51]
Team, T.H.: Hunyuan3d 1.0: A unified framework for text-to-3d and image-to-3d generation (2024)
2024
-
[52]
Team, T.H.: Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation (2025)
2025
-
[53]
Team, T.H.: Hunyuan3d 2.1: From images to high-fidelity 3d assets with production-ready pbr material (2025)
2025
-
[54]
IEEE Transactions on pattern analysis and machine intelligence 13(4), 376–380 (2002)
Umeyama, S.: Least-squares estimation of transformation parameters between two point patterns. IEEE Transactions on pattern analysis and machine intelligence 13(4), 376–380 (2002)
2002
-
[55]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wald, J., Avetisyan, A., Navab, N., Tombari, F., Nießner, M.: Rio: 3d object instance re-localization in changing indoor environments. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7658–7667 (2019)
2019
-
[56]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (2025)
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (2025)
2025
-
[57]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, Z., Bovik, A., Sheikh, H., Simoncelli, E.: Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing 13(4), 600–612 (2004).https://doi.org/10.1109/TIP.2003.819861
-
[58]
Wen, H., Huang, Z., Wang, Y., Chen, X., Qiao, Y., Sheng, L.: Ouroboros3d: Image- to-3d generation via 3d-aware recursive diffusion. arXiv preprint arXiv:2406.03184 (2024)
-
[59]
arXiv preprint arXiv:2505.23747 (2025)
Wu, D., Liu, F., Hung, Y.H., Duan, Y.: Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence. arXiv preprint arXiv:2505.23747 (2025)
-
[60]
arXiv preprint arXiv:2405.14832 (2024)
Wu, S., Lin, Y., Zhang, F., Zeng, Y., Xu, J., Torr, P., Cao, X., Yao, Y.: Direct3d: Scalable image-to-3d generation via 3d latent diffusion transformer. arXiv preprint arXiv:2405.14832 (2024)
-
[61]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Xia, C., Zhang, S., Liu, F., Liu, C., Hirunyaratsameewong, K., Duan, Y.: Scene- painter: Semantically consistent perpetual 3d scene generation with concept re- lation alignment. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 28808–28817 (2025)
2025
- [62]
-
[63]
arXiv preprint arXiv:2412.01506 (2024)
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. arXiv preprint arXiv:2412.01506 (2024)
-
[64]
Xu, J., Cheng, W., Gao, Y., Wang, X., Gao, S., Shan, Y.: Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models. arXiv preprint arXiv:2404.07191 (2024)
work page internal anchor Pith review arXiv 2024
-
[65]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yang, Y., Sun, F.Y., Weihs, L., VanderBilt, E., Herrasti, A., Han, W., Wu, J., Haber, N., Krishna, R., Liu, L., et al.: Holodeck: Language guided generation of 3d embodied ai environments. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16227–16237 (2024)
2024
-
[66]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yang,Z.,Yang,B.,Dong,W.,Cao,C.,Cui,L.,Ma,Y.,Cui,Z.,Bao,H.:Instascene: Towards complete 3d instance decomposition and reconstruction from cluttered scenes. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7771–7781 (2025)
2025
-
[67]
ACM Transactions on Graphics (TOG)44(4), 1–19 (2025) Title Suppressed Due to Excessive Length 19
Yao, K., Zhang, L., Yan, X., Zeng, Y., Zhang, Q., Xu, L., Yang, W., Gu, J., Yu, J.: Cast: Component-aligned 3d scene reconstruction from an rgb image. ACM Transactions on Graphics (TOG)44(4), 1–19 (2025) Title Suppressed Due to Excessive Length 19
2025
-
[68]
Ye, C., Wu, Y., Lu, Z., Chang, J., Guo, X., Zhou, J., Zhao, H., Han, X.: Hi3dgen: High-fidelity 3d geometry generation from images via normal bridging. arXiv preprint arXiv:2503.22236 (2025)
-
[69]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yeshwanth, C., Liu, Y.C., Nießner, M., Dai, A.: Scannet++: A high-fidelity dataset of 3d indoor scenes. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12–22 (2023)
2023
-
[70]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yu,H.,Jia,B.,Chen,Y.,Yang,Y.,Li,P.,Su,R.,Li,J.,Li,Q.,Liang,W.,Zhu,S.C., et al.: Metascenes: Towards automated replica creation for real-world 3d scans. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 1667–1679 (2025)
2025
-
[71]
Advances in neural information processing systems35, 25018–25032 (2022)
Yu, Z., Peng, S., Niemeyer, M., Sattler, T., Geiger, A.: Monosdf: Exploring monoc- ular geometric cues for neural implicit surface reconstruction. Advances in neural information processing systems35, 25018–25032 (2022)
2022
-
[72]
Clay: A controllable large-scale generative model for creating high-quality 3d assets, 2024
Zhang, L., Wang, Z., Zhang, Q., Qiu, Q., Pang, A., Jiang, H., Yang, W., Xu, L., Yu, J.: Clay: A controllable large-scale generative model for creating high-quality 3d assets. arXiv preprint arXiv:2406.13897 (2024)
-
[73]
In: CVPR (2018)
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR (2018)
2018
-
[74]
Advances in neural information processing sys- tems36, 73969–73982 (2023)
Zhao, Z., Liu, W., Chen, X., Zeng, X., Wang, R., Cheng, P., Fu, B., Chen, T., Yu, G., Gao, S.: Michelangelo: Conditional 3d shape generation based on shape-image- text aligned latent representation. Advances in neural information processing sys- tems36, 73969–73982 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.