Recognition: unknown
Toward Visually Realistic Simulation: A Benchmark for Evaluating Robot Manipulation in Simulation
Pith reviewed 2026-05-08 09:02 UTC · model grok-4.3
The pith
VISER benchmark correlates sim and real robot performance at 0.92
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
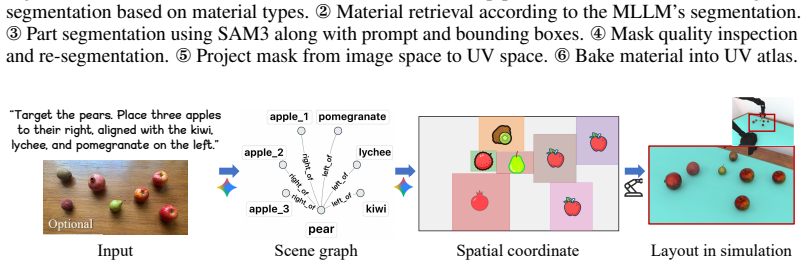
We propose VISER, a visually realistic benchmark for robot manipulation in simulation. It features a high-fidelity dataset of over 1,000 3D assets with PBR materials, generated via an MLLM pipeline for material-aware part segmentation and material retrieval. Scenes are created through curated layouts or generation, supporting diverse tasks like grasping, placing, and long-horizon manipulation. Evaluations across policies demonstrate an average Pearson correlation coefficient of 0.92 between simulation and real-world performance.
What carries the argument
The VISER benchmark, built on a dataset of physically-based rendering (PBR) 3D assets generated by an automated Multi-modal Large Language Model (MLLM) pipeline for material-aware segmentation and retrieval.
Load-bearing premise
That the primary cause of the sim-to-real gap is insufficient realism in lighting and materials, and that the MLLM-based material generation is accurate enough not to introduce new errors in perception.
What would settle it
Measuring the Pearson correlation for a new set of policies or tasks and finding it significantly below 0.92, or observing that policies optimized in VISER fail to perform well in real-world tests despite high sim scores.
Figures











read the original abstract
Reliable simulation evaluation of robot manipulation policies serves as a high-fidelity proxy for real-world performance. Although existing benchmarks cover a wide range of task categories, they lack visual realism, creating a large domain gap between simulation and reality. This undermines the reliability of simulation-based evaluation in predicting real-world performance. To mitigate the sim-to-real visual gap, we conduct a systematic analysis to isolate the effects of lighting and material. Our results show that these factors play a critical role in geometric reasoning and spatial grounding, yet are largely overlooked in existing benchmarks. Motivated by the analysis, we propose VISER, a visually realistic benchmark for evaluating robot manipulation in simulation. VISER features a high-fidelity dataset of over 1,000 3D assets with physically-based rendering (PBR) materials, along with 3D scenes created from these assets through curated layouts or generation. To this end, we propose an automated pipeline leveraging Multi-modal Large Language Models (MLLMs) for material-aware part segmentation and material retrieval, enabling scalable generation of physically plausible assets. Building on the high-fidelity 3D asset dataset, we construct diverse evaluation tasks, such as grasping, placing, and long-horizon tasks, enabling scalable and reproducible assessment of Vision-Language-Action (VLA) models. Our benchmark shows a strong correlation between simulation and real-world performance, achieving an average Pearson correlation coefficient of 0.92 across different policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VISER, a benchmark for robot manipulation in simulation featuring a dataset of over 1,000 3D assets with PBR materials generated via an automated MLLM pipeline for material-aware part segmentation and retrieval. It includes an analysis isolating the effects of lighting and materials on geometric reasoning, constructs diverse tasks (grasping, placing, long-horizon), and reports an average Pearson correlation of 0.92 between simulation and real-world policy performance as evidence that visual realism mitigates the sim-to-real gap.
Significance. If the correlation is supported by detailed, reproducible experiments and the asset pipeline is validated, VISER could serve as a scalable, high-fidelity proxy for real-world evaluation of VLA models, addressing a key limitation in existing manipulation benchmarks.
major comments (2)
- [Abstract] Abstract: The headline result of an average Pearson correlation coefficient of 0.92 is presented without any information on the number of policies tested, task selection criteria, number of trials per policy, statistical methods, error bars, p-values, or controls for non-visual sim-to-real factors (e.g., dynamics mismatch or sensor noise). This absence leaves the central empirical claim without visible supporting evidence.
- [Automated pipeline for asset generation] Automated pipeline section: The correlation result depends on the MLLM pipeline producing accurate part segmentation and PBR material parameters that support reliable geometric reasoning and grasping. No quantitative validation is provided (e.g., material reflectance/roughness error vs. ground truth, segmentation metrics, or human visual fidelity ratings), so any observed sim-real match could be an artifact of the specific policies/scenes rather than proof that lighting/material realism closes the gap.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights opportunities to strengthen the presentation of our empirical results and the validation of our asset generation pipeline. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline result of an average Pearson correlation coefficient of 0.92 is presented without any information on the number of policies tested, task selection criteria, number of trials per policy, statistical methods, error bars, p-values, or controls for non-visual sim-to-real factors (e.g., dynamics mismatch or sensor noise). This absence leaves the central empirical claim without visible supporting evidence.
Authors: We agree that the abstract would benefit from additional context to allow readers to better evaluate the robustness of the 0.92 correlation. In the revised manuscript, we will expand the abstract to specify the experimental details: the correlation is computed over 5 VLA policies across 3 task categories (grasping, placing, long-horizon), using 50 trials per policy-task pair, with Pearson correlation, p-values, and confidence intervals reported. We will also note that dynamics and sensor parameters were matched between simulation and real-world setups to isolate visual factors. Full protocols remain in Section 4.3. revision: yes
-
Referee: [Automated pipeline for asset generation] Automated pipeline section: The correlation result depends on the MLLM pipeline producing accurate part segmentation and PBR material parameters that support reliable geometric reasoning and grasping. No quantitative validation is provided (e.g., material reflectance/roughness error vs. ground truth, segmentation metrics, or human visual fidelity ratings), so any observed sim-real match could be an artifact of the specific policies/scenes rather than proof that lighting/material realism closes the gap.
Authors: We thank the referee for this observation and agree that quantitative validation would provide stronger support for the pipeline's role in the observed correlation. While the manuscript currently emphasizes qualitative examples and end-to-end results, we will add quantitative metrics in the revision, including segmentation IoU scores on a held-out set and a human visual fidelity study (average rating and inter-rater agreement). We will also include an ablation on material realism to demonstrate its contribution to geometric reasoning and policy performance, helping rule out artifacts from specific scenes. revision: yes
Circularity Check
No circularity: correlation is empirical comparison, not derived by construction
full rationale
The paper's headline result is an observed Pearson correlation of 0.92 between success rates of policies run in the VISER simulator and the same policies run in the real world. This quantity is obtained by direct experimental measurement after asset generation and policy execution; it is not obtained by fitting parameters to the target correlation, by self-definition of any metric, or by any uniqueness theorem imported from prior self-citations. The MLLM pipeline is used only to produce the 3D assets; the subsequent correlation is an independent validation step whose value is not presupposed by the pipeline's design. No equations or derivation steps in the provided text reduce the reported correlation to its own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Lighting and material properties are the primary overlooked factors driving the visual sim-to-real gap in geometric reasoning for manipulation tasks
- domain assumption Multi-modal large language models can perform reliable material-aware part segmentation and material retrieval for physically plausible asset creation
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review arXiv 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. a...
work page internal anchor Pith review arXiv 2025
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky. π0: A visi...
work page internal anchor Pith review arXiv 2026
-
[4]
ShapeNet: An Information-Rich 3D Model Repository
Angel X. Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, and Fisher Yu. Shapenet: An information-rich 3d model repository, 2015. URL https://arxiv.org/abs/ 1512.03012
work page internal anchor Pith review arXiv 2015
-
[5]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, Weiliang Deng, Yubin Guo, Tian Nian, Xuanbing Xie, Qiangyu Chen, Kailun Su, Tianling Xu, Guodong Liu, Mengkang Hu, Huan ang Gao, Kaixuan Wang, Zhixuan Liang, Yusen Qin, Xiaokang Yang, Ping Luo, and Yao Mu. Robotwin 2.0: A scalable d...
work page internal anchor Pith review arXiv 2025
-
[6]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration et al. Open X-Embodiment: Robotic learning datasets and RT-X models.https://arxiv.org/abs/2310.08864, 2023
work page internal anchor Pith review arXiv 2023
-
[7]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects, 2022. URLhttps://arxiv.org/abs/2212.08051
-
[8]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis, 2024. URL https://arxiv.org/abs/ 2403.03206
work page internal anchor Pith review arXiv 2024
-
[9]
Ye Fang, Zeyi Sun, Tong Wu, Jiaqi Wang, Ziwei Liu, Gordon Wetzstein, and Dahua Lin. Make- it-real: Unleashing large multimodal model for painting 3d objects with realistic materials, 2024. URLhttps://arxiv.org/abs/2404.16829
-
[10]
Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation
Zipeng Fu, Tony Z. Zhao, and Chelsea Finn. Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation, 2024. URL https://arxiv.org/abs/ 2401.02117
work page internal anchor Pith review arXiv 2024
-
[11]
Generative detail enhancement for physically based materials
Saeed Hadadan, Benedikt Bitterli, Tizian Zeltner, Jan Novák, Fabrice Rousselle, Jacob Munkberg, Jon Hasselgren, Bartlomiej Wronski, and Matthias Zwicker. Generative detail enhancement for physically based materials. InProceedings of the Special Interest Group on 10 Computer Graphics and Interactive Techniques Conference Conference Papers, SIGGRAPH Confere...
-
[12]
Materialmvp: Illumination- invariant material generation via multi-view pbr diffusion, 2025
Zebin He, Mingxin Yang, Shuhui Yang, Yixuan Tang, Tao Wang, Kaihao Zhang, Guanying Chen, Yuhong Liu, Jie Jiang, Chunchao Guo, and Wenhan Luo. Materialmvp: Illumination- invariant material generation via multi-view pbr diffusion, 2025. URL https://arxiv.org/ abs/2503.10289
-
[13]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsc...
work page internal anchor Pith review arXiv 2025
-
[14]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model, 2024. URL https://arxiv. org/abs/...
work page internal anchor Pith review arXiv 2024
-
[15]
arXiv preprint arXiv:2506.16504 , year=
Zeqiang Lai, Yunfei Zhao, Haolin Liu, Zibo Zhao, Qingxiang Lin, Huiwen Shi, Xianghui Yang, Mingxin Yang, Shuhui Yang, Yifei Feng, Sheng Zhang, Xin Huang, Di Luo, Fan Yang, Fang Yang, Lifu Wang, Sicong Liu, Yixuan Tang, Yulin Cai, Zebin He, Tian Liu, Yuhong Liu, Jie Jiang, Linus, Jingwei Huang, and Chunchao Guo. Hunyuan3d 2.5: Towards high-fidelity 3d asse...
-
[16]
Lattice: Democratize high-fidelity 3d generation at scale.arXiv preprint arXiv:2512.03052, 2025
Zeqiang Lai, Yunfei Zhao, Zibo Zhao, Haolin Liu, Qingxiang Lin, Jingwei Huang, Chunchao Guo, and Xiangyu Yue. Lattice: Democratize high-fidelity 3d generation at scale, 2025. URL https://arxiv.org/abs/2512.03052
-
[17]
Zeqiang Lai, Yunfei Zhao, Zibo Zhao, Xin Yang, Xin Huang, Jingwei Huang, Xiangyu Yue, and Chunchao Guo. Natex: Seamless texture generation as latent color diffusion, 2025. URL https://arxiv.org/abs/2511.16317
-
[18]
Chengshu Li, Ruohan Zhang, Josiah Wong, Cem Gokmen, Sanjana Srivastava, Roberto Martín- Martín, Chen Wang, Gabrael Levine, Wensi Ai, Benjamin Martinez, Hang Yin, Michael Lingelbach, Minjune Hwang, Ayano Hiranaka, Sujay Garlanka, Arman Aydin, Sharon Lee, Jiankai Sun, Mona Anvari, Manasi Sharma, Dhruva Bansal, Samuel Hunter, Kyu-Young Kim, Alan Lou, Caleb R...
-
[19]
Evaluating real-world robot manipulation policies in simulation,
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su, Quan Vuong, and Ted Xiao. Evaluating real-world robot manipulation policies in simulation,
-
[20]
URLhttps://arxiv.org/abs/2405.05941
work page internal anchor Pith review arXiv
-
[21]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling, 2023. URLhttps://arxiv.org/abs/2210.02747
work page internal anchor Pith review arXiv 2023
-
[22]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning, 2023. URL https: //arxiv.org/abs/2306.03310
work page internal anchor Pith review arXiv 2023
-
[23]
Partfield: Learning 3d feature fields for part segmentation and beyond, 2025
Minghua Liu, Mikaela Angelina Uy, Donglai Xiang, Hao Su, Sanja Fidler, Nicholas Sharp, and Jun Gao. Partfield: Learning 3d feature fields for part segmentation and beyond, 2025. URL https://arxiv.org/abs/2504.11451. 11
-
[24]
UnCommon Objects in 3D.arXiv preprint arXiv:2501.07574, 2025
Xingchen Liu, Piyush Tayal, Jianyuan Wang, Jesus Zarzar, Tom Monnier, Konstantinos Tertikas, Jiali Duan, Antoine Toisoul, Jason Y . Zhang, Natalia Neverova, Andrea Vedaldi, Roman Shapovalov, and David Novotny. Uncommon objects in 3d, 2025. URL https://arxiv.org/ abs/2501.07574
-
[25]
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks, 2022. URL https://arxiv.org/abs/2112.03227
-
[26]
Tongzhou Mu, Zhan Ling, Fanbo Xiang, Derek Yang, Xuanlin Li, Stone Tao, Zhiao Huang, Zhiwei Jia, and Hao Su. Maniskill: Generalizable manipulation skill benchmark with large-scale demonstrations, 2021. URLhttps://arxiv.org/abs/2107.14483
-
[27]
RoboTwin: Dual-arm robot benchmark with generative digital twins.arXiv preprint arXiv:2409.02920,
Yao Mu, Tianxing Chen, Shijia Peng, Zanxin Chen, Zeyu Gao, Yude Zou, Lunkai Lin, Zhiqiang Xie, and Ping Luo. Robotwin: Dual-arm robot benchmark with generative digital twins (early version), 2025. URLhttps://arxiv.org/abs/2409.02920
-
[28]
Robocasa: Large-scale simulation of everyday tasks for generalist robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots. InRobotics: Science and Systems (RSS), 2024
2024
-
[29]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers, 2023. URL https://arxiv.org/abs/2212.09748
work page internal anchor Pith review arXiv 2023
-
[30]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion, 2022. URLhttps://arxiv.org/abs/2209.14988
work page internal anchor Pith review arXiv 2022
-
[31]
Aaditya Singh, Adam Fry, et al. Openai gpt-5 system card, 2025. URL https://arxiv.org/ abs/2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Habitat 2.0: Training home assistants to rearrange their habitat
Andrew Szot, Alex Clegg, Eric Undersander, Erik Wijmans, Yili Zhao, John Turner, Noah Maestre, Mustafa Mukadam, Devendra Chaplot, Oleksandr Maksymets, Aaron Gokaslan, Vladimir V ondrus, Sameer Dharur, Franziska Meier, Wojciech Galuba, Angel Chang, Zsolt Kira, Vladlen Koltun, Jitendra Malik, Manolis Savva, and Dhruv Batra. Habitat 2.0: Training home assist...
-
[33]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team et al. Gemini: A family of highly capable multimodal models, 2025. URL https://arxiv.org/abs/2312.11805
work page internal anchor Pith review arXiv 2025
-
[34]
arXiv preprint arXiv:2510.03342 (2025)
Gemini Robotics Team et al. Gemini robotics 1.5: Pushing the frontier of generalist robots with advanced embodied reasoning, thinking, and motion transfer, 2025. URL https://arxiv. org/abs/2510.03342
-
[35]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yunliang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy, 2024. URL https://arxiv.org/abs/2405.12213
work page internal anchor Pith review arXiv 2024
-
[36]
arXiv preprint arXiv:2403.02151 , year=
Dmitry Tochilkin, David Pankratz, Zexiang Liu, Zixuan Huang, Adam Letts, Yangguang Li, Ding Liang, Christian Laforte, Varun Jampani, and Yan-Pei Cao. Triposr: Fast 3d object reconstruction from a single image, 2024. URLhttps://arxiv.org/abs/2403.02151
-
[37]
In: 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–5033. IEEE, 2012. doi: 10.1109/IROS.2012.6386109
-
[38]
Vbench: Comprehensive benchmark suite for video generative models
Giuseppe Vecchio and Valentin Deschaintre. Matsynth: A modern pbr materials dataset. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), page 22109–22118. IEEE, 2024. doi: 10.1109/cvpr52733.2024.02087. URL http://dx.doi.org/ 10.1109/CVPR52733.2024.02087. 12
-
[39]
Bridgedata v2: A dataset for robot learning at scale, 2024
Homer Walke, Kevin Black, Abraham Lee, Moo Jin Kim, Max Du, Chongyi Zheng, Tony Zhao, Philippe Hansen-Estruch, Quan Vuong, Andre He, Vivek Myers, Kuan Fang, Chelsea Finn, and Sergey Levine. Bridgedata v2: A dataset for robot learning at scale, 2024. URL https://arxiv.org/abs/2308.12952
-
[40]
Manitwin: Scaling data-generation-ready digital object dataset to 100k,
Kaixuan Wang, Tianxing Chen, Jiawei Liu, Honghao Su, Shaolong Zhu, Minxuan Wang, Zixuan Li, Yue Chen, Huan ang Gao, Yusen Qin, Jiawei Wang, Qixuan Zhang, Lan Xu, Jingyi Yu, Yao Mu, and Ping Luo. Manitwin: Scaling data-generation-ready digital object dataset to 100k,
- [41]
-
[42]
Partuv: Part-based uv unwrapping of 3d meshes, 2026
Zhaoning Wang, Xinyue Wei, Ruoxi Shi, Xiaoshuai Zhang, Hao Su, and Minghua Liu. Partuv: Part-based uv unwrapping of 3d meshes, 2026. URL https://arxiv.org/abs/2511.16659
-
[43]
Xinyue Wei, Minghua Liu, Zhan Ling, and Hao Su. Approximate convex decomposition for 3d meshes with collision-aware concavity and tree search.ACM Transactions on Graphics, 41(4):1–18, July 2022. ISSN 1557-7368. doi: 10.1145/3528223.3530103. URL http: //dx.doi.org/10.1145/3528223.3530103
-
[44]
Chang, Leonidas J
Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, Li Yi, Angel X. Chang, Leonidas J. Guibas, and Hao Su. SAPIEN: A simulated part-based interactive environment. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
2020
-
[45]
CoRR abs/2105.15203(2021),https://arxiv.org/abs/2105.15203
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transformers, 2021. URLhttps://arxiv.org/abs/2105.15203
-
[46]
Clay: A controllable large-scale generative model for creating high-quality 3d assets, 2024
Longwen Zhang, Ziyu Wang, Qixuan Zhang, Qiwei Qiu, Anqi Pang, Haoran Jiang, Wei Yang, Lan Xu, and Jingyi Yu. Clay: A controllable large-scale generative model for creating high-quality 3d assets, 2024. URLhttps://arxiv.org/abs/2406.13897
-
[47]
Mapa: Text-driven photorealistic material painting for 3d shapes, 2025
Shangzan Zhang, Sida Peng, Tao Xu, Yuanbo Yang, Tianrun Chen, Nan Xue, Yujun Shen, Hujun Bao, Ruizhen Hu, and Xiaowei Zhou. Mapa: Text-driven photorealistic material painting for 3d shapes, 2025. URLhttps://arxiv.org/abs/2404.17569
-
[48]
arXiv preprint arXiv:2412.18194 , year=
Shiduo Zhang, Zhe Xu, Peiju Liu, Xiaopeng Yu, Yuan Li, Qinghui Gao, Zhaoye Fei, Zhangyue Yin, Zuxuan Wu, Yu-Gang Jiang, and Xipeng Qiu. Vlabench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks, 2024. URL https://arxiv.org/abs/2412.18194
-
[49]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, Ya-Qin Zhang, Jiangmiao Pang, Jingjing Liu, Tai Wang, and Xianyuan Zhan. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model, 2025. URLhttps://arxiv.org/abs/2510.10274
work page internal anchor Pith review arXiv 2025
-
[50]
Liming Zheng, Feng Yan, Fanfan Liu, Chengjian Feng, Zhuoliang Kang, and Lin Ma. Robocas: A benchmark for robotic manipulation in complex object arrangement scenarios, 2024. URL https://arxiv.org/abs/2407.06951. 13 A Technical appendices and supplementary material A.1 3D Asset Dataset Overview We present the overview of our 3D asset dataset in Fig. 10 and ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.