WBench: A Comprehensive Multi-turn Benchmark for Interactive Video World Model Evaluation
Pith reviewed 2026-06-29 22:54 UTC · model grok-4.3
The pith
WBench introduces a multi-turn benchmark evaluating interactive video world models on five dimensions and finds no model performs strongly across all.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
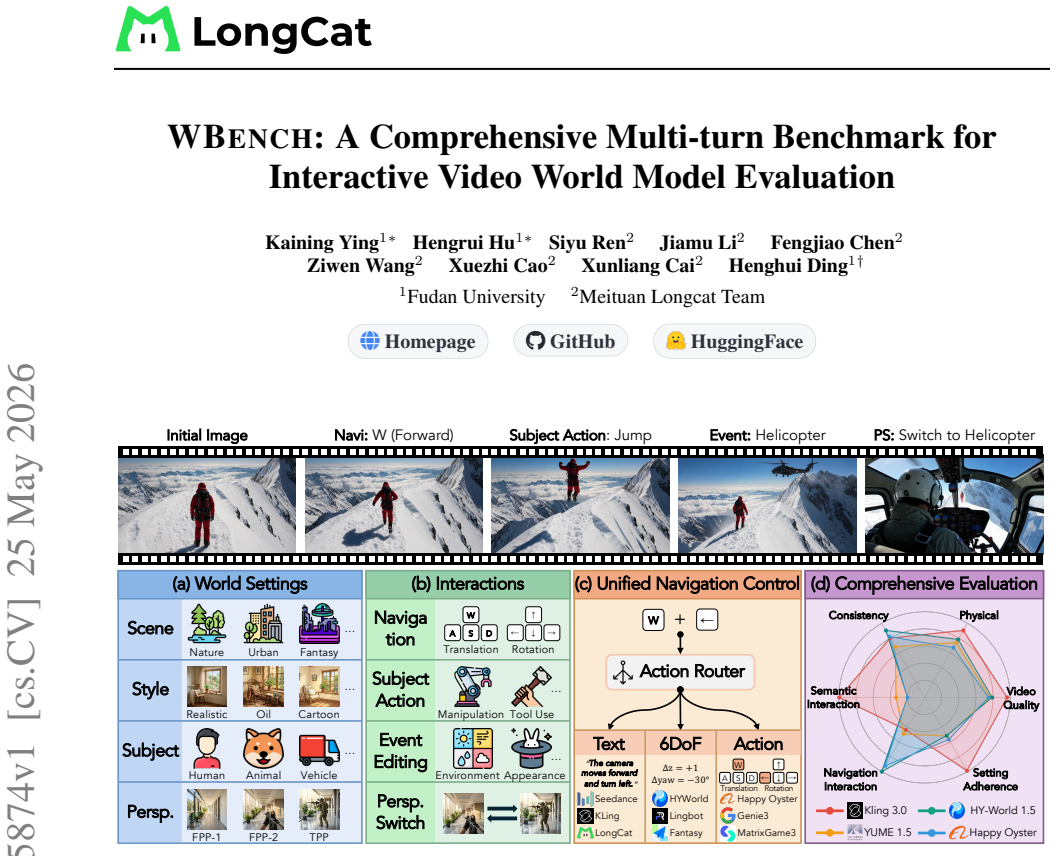
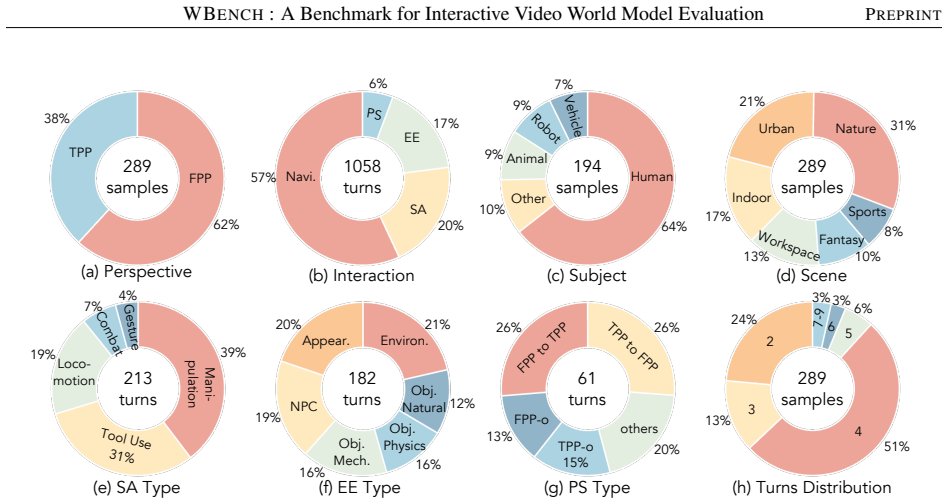
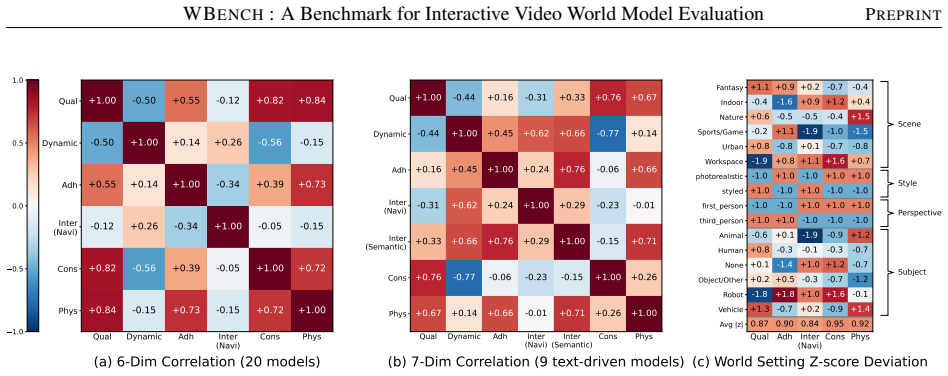
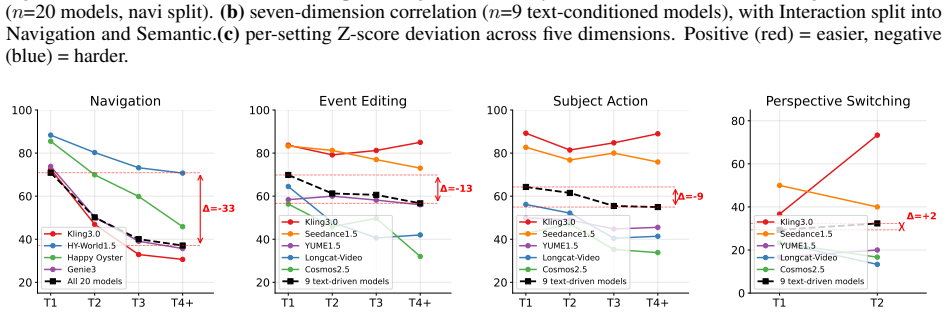
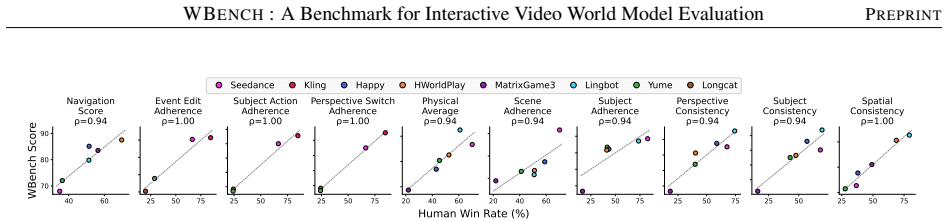
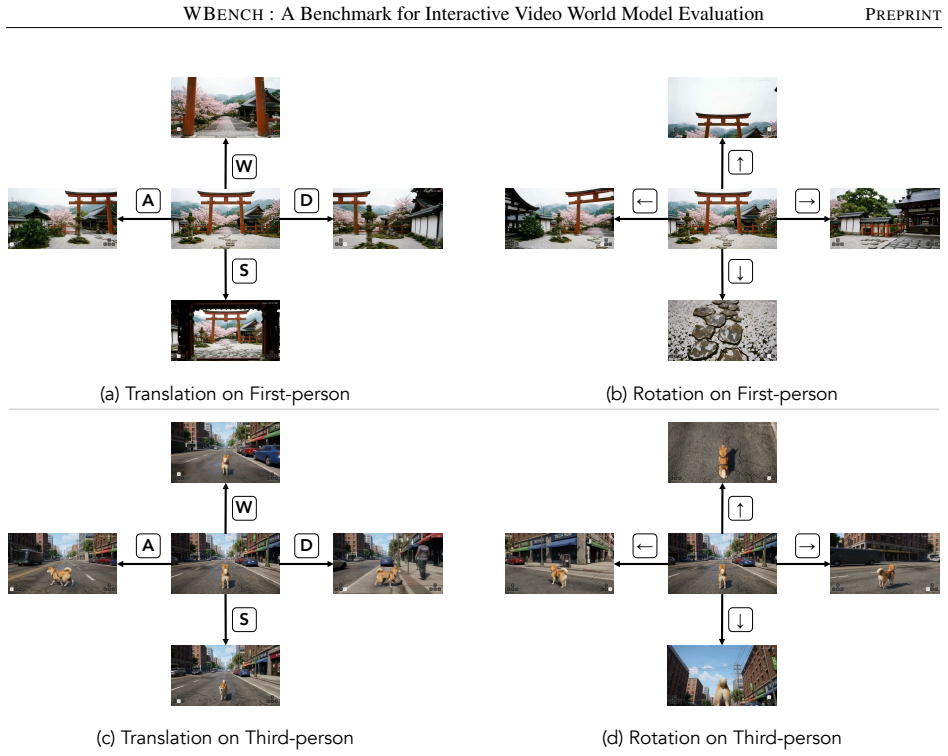
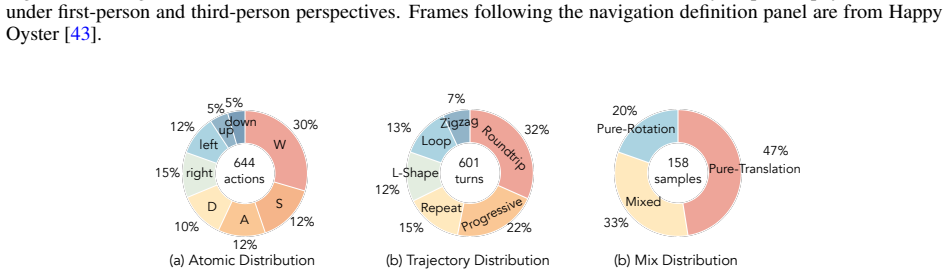
WBench supplies 289 test cases and 1058 interaction turns that specify world settings and multi-turn sequences covering navigation, subject action, event editing, and perspective switching, with unified support for text, 6-DoF pose, and discrete-action controls; its 22 automatic sub-metrics, validated against human judgments, demonstrate that no model among the 20 evaluated performs strongly across the five dimensions of video quality, setting adherence, interaction adherence, consistency, and physics compliance.
What carries the argument
The WBench benchmark itself, structured around its five evaluation dimensions and the set of 22 automatic sub-metrics that combine specialist vision models with large multimodal models.
If this is right
- Systematic multi-turn testing across navigation, action, editing, and perspective changes is required to expose consistency and adherence failures invisible in single-turn evaluations.
- Unified support for text, pose, and discrete-action inputs allows direct comparison of models with different native control interfaces.
- Diagnostic per-dimension scores reveal characteristic model weaknesses that can guide targeted improvements rather than uniform scaling.
- Validated automatic metrics enable scalable evaluation without relying solely on costly human annotation for every test case.
Where Pith is reading between the lines
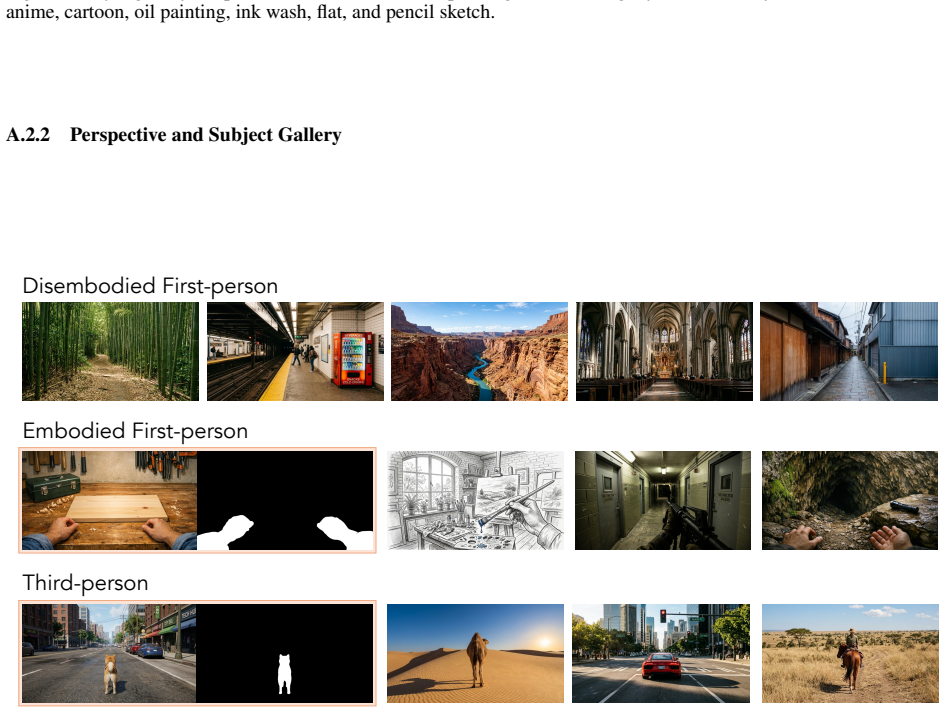
- The benchmark's coverage of first- and third-person perspectives may help identify viewpoint-dependent failure modes that transfer to embodied agents.
- If the five dimensions prove partially independent, future architectures may need explicit modular components rather than end-to-end training alone.
- Extending the test cases to longer interaction sequences could surface compounding physics violations not captured in the current 1058 turns.
- The finding that no model dominates all dimensions suggests that leaderboard rankings based on single metrics will continue to mislead development priorities.
Load-bearing premise
The 22 automatic sub-metrics accurately reflect the five dimensions when validated against human judgments.
What would settle it
A model that scores at the top across all five dimensions on the full set of WBench test cases, or a large mismatch between the automatic sub-metric rankings and fresh human judgments on the same outputs.
Figures











read the original abstract
Interactive world models are advancing rapidly, yet existing benchmarks cover only part of the required competencies, leaving no unified standard for systematic evaluation. To fill this gap, we introduce WBench, a comprehensive multi-turn benchmark for interactive world model evaluation along five dimensions, namely video quality, setting adherence, interaction adherence, consistency, and physics compliance. WBench contains 289 test cases and 1,058 interaction turns, where each case specifies a world setting and a multi-turn interaction sequence, covering diverse scenes, styles, subjects, and both first- and third-person perspectives, together with four interaction types, including navigation, subject action, event editing, and perspective switching. For navigation, WBench unifies text, 6-DoF pose, and discrete-action control, enabling evaluation of models with different native input interfaces. Evaluation uses 22 automatic sub-metrics that combine specialist vision models with large multimodal models, and all metrics are validated against human judgments. Across 20 state-of-the-art models, we find that no single model performs strongly across all dimensions. We provide detailed diagnostic insights into the characteristic strengths, weaknesses, and open challenges of each model. Code and data are available at https://github.com/meituan-longcat/WBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces WBench, a multi-turn benchmark for interactive video world model evaluation along five dimensions (video quality, setting adherence, interaction adherence, consistency, and physics compliance). It contains 289 test cases and 1,058 interaction turns covering diverse scenes, styles, subjects, perspectives, and four interaction types, with unified control interfaces for navigation. Evaluation relies on 22 automatic sub-metrics that combine specialist vision models with large multimodal models; these metrics are stated to be validated against human judgments. Across 20 state-of-the-art models, the paper reports that no single model performs strongly across all dimensions and provides diagnostic insights into model strengths and weaknesses. Code and data are released at a public GitHub repository.
Significance. If the automatic metrics are shown to be faithful proxies, WBench would fill an important gap by providing a unified, multi-turn standard for interactive world models and would usefully document complementary model capabilities. The public release of code and data is a clear strength that supports reproducibility.
major comments (1)
- [Abstract] Abstract: the statement that 'all metrics are validated against human judgments' supplies no quantitative support (correlation coefficients, number of raters, inter-rater agreement, or per-dimension breakdown). Because the headline result that 'no single model performs strongly across all dimensions' is produced entirely by the 22 automatic sub-metrics, the missing validation statistics are load-bearing for the central claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment point by point below and commit to revisions that directly strengthen the presentation of our validation claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that 'all metrics are validated against human judgments' supplies no quantitative support (correlation coefficients, number of raters, inter-rater agreement, or per-dimension breakdown). Because the headline result that 'no single model performs strongly across all dimensions' is produced entirely by the 22 automatic sub-metrics, the missing validation statistics are load-bearing for the central claim.
Authors: We agree that the abstract should supply quantitative support for the claim that the 22 automatic sub-metrics are validated against human judgments. The manuscript body contains the relevant validation details (including correlations, rater counts, agreement metrics, and per-dimension results), but these are not summarized in the abstract. We will revise the abstract to include a concise quantitative statement of the validation results, thereby making the load-bearing evidence for the headline finding explicit and transparent. revision: yes
Circularity Check
No circularity: benchmark construction is external to evaluated models
full rationale
The paper introduces WBench as an independent benchmark with 289 test cases and 22 automatic sub-metrics for five evaluation dimensions. The central result (no model strong across all dimensions) is produced by applying these metrics to 20 external models. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text; the metrics are presented as combining specialist vision models with large multimodal models and validated externally against human judgments. The work is therefore self-contained as an empirical evaluation framework rather than a closed derivation.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 3 Pith papers
-
Current World Models Lack a Persistent State Core
Current world models fail to evolve internal state when unobserved and instead resume scenes at the last observed state, as diagnosed by the new WRBench benchmark across 23 models and 9600 videos.
-
Einstein World Models
Einstein World Models integrate visual rollouts from a callable world-module into LLM reasoning traces to support complex thought beyond language.
-
WorldOlympiad: Can Your World Model Survive a Triathlon?
WorldOlympiad is a new benchmark decomposing world-model evaluation into physical, geometry, and interaction tracks using segmentation, MLLM judges, Gaussian splatting, and action prompts on diverse scenarios.
Reference graph
Works this paper leans on
-
[1]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[2]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Leo Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, et al. Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
2024
-
[6]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning, 2024
2024
-
[7]
Genie 2: A large-scale foundation world model
Jack Parker-Holder, Philip Ball, Jake Bruce, Vibhavari Dasagi, Kristian Holsheimer, Christos Kaplanis, Alexandre Moufarek, Guy Scully, Jeremy Shar, Jimmy Shi, et al. Genie 2: A large-scale foundation world model. https://deepmind.google/ discover/blog/genie-2-a-large-scale-foundation-world-model/, 2024. 11 WBENCH: A Benchmark for Interactive Video World M...
2024
-
[8]
Philip J. Ball, Jakob Bauer, Frank Belletti, Bethanie Brownfield, Ariel Ephrat, Shlomi Fruchter, Agrim Gupta, Kristian Holsheimer, Aleksander Holynski, Jiri Hron, Christos Kaplanis, Marjorie Limont, Matt McGill, Yanko Oliveira, Jack Parker- Holder, Frank Perbet, Guy Scully, Jeremy Shar, Stephen Spencer, Omer Tov, Ruben Villegas, Emma Wang, Jessica Yung, C...
2025
-
[9]
Matrix-game 2.0: An open-source real-time and streaming interactive world model
Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Yangyang Ren, et al. Matrix-game 2.0: An open-source real-time and streaming interactive world model.arXiv preprint arXiv:2508.13009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
Zile Wang, Zexiang Liu, Jaixing Li, Kaichen Huang, Baixin Xu, Fei Kang, Mengyin An, Peiyu Wang, Biao Jiang, Yichen Wei, et al. Matrix-game 3.0: Real-time and streaming interactive world model with long-horizon memory.arXiv preprint arXiv:2604.08995, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Jiaqi Li, Junshu Tang, Zhiyong Xu, Longhuang Wu, Yuan Zhou, Shuai Shao, Tianbao Yu, Zhiguo Cao, and Qinglin Lu. Hunyuan- gamecraft: High-dynamic interactive game video generation with hybrid history condition.arXiv preprint arXiv:2506.17201, 2 (3):6, 2025
-
[12]
Junshu Tang, Jiacheng Liu, Jiaqi Li, Longhuang Wu, Haoyu Yang, Penghao Zhao, Siruis Gong, Xiang Yuan, Shuai Shao, Linfeng Zhang, et al. Hunyuan-gamecraft-2: Instruction-following interactive game world model.arXiv preprint arXiv:2511.23429, 2025
-
[13]
GAIA-1: A Generative World Model for Autonomous Driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving.arXiv preprint arXiv:2309.17080, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Vista: A generalizable driving world model with high fidelity and versatile controllability.Advances in Neural Information Processing Systems, 37:91560–91596, 2024
Shenyuan Gao, Jiazhi Yang, Li Chen, Kashyap Chitta, Yihang Qiu, Andreas Geiger, Jun Zhang, and Hongyang Li. Vista: A generalizable driving world model with high fidelity and versatile controllability.Advances in Neural Information Processing Systems, 37:91560–91596, 2024
2024
-
[15]
Learning Interactive Real-World Simulators
Sherry Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Leslie Kaelbling, Dale Schuurmans, and Pieter Abbeel. Learning interactive real-world simulators.arXiv preprint arXiv:2310.06114, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Fangqi Zhu, Hongtao Wu, Song Guo, Yuxiao Liu, Chilam Cheang, and Tao Kong. Irasim: Learning interactive real-robot action simulators.arXiv preprint arXiv:2406.14540, 1(2):3, 2024
-
[17]
Hy-world 1.5: A systematic framework for interactive world modeling with real-time latency and geometric consistency.arXiv preprint, 2025
Team HunyuanWorld. Hy-world 1.5: A systematic framework for interactive world modeling with real-time latency and geometric consistency.arXiv preprint, 2025
2025
-
[18]
Yume: An interactive world generation model.arXiv preprint arXiv:2507.17744, 2025
Xiaofeng Mao, Shaoheng Lin, Zhen Li, Chuanhao Li, Wenshuo Peng, Tong He, Jiangmiao Pang, Mingmin Chi, Yu Qiao, and Kaipeng Zhang. Yume: An interactive world generation model.arXiv preprint arXiv:2507.17744, 2025
-
[19]
Yume-1.5: A text-controlled interactive world generation model.arXiv preprint arXiv:2512.22096, 2025
Xiaofeng Mao, Zhen Li, Chuanhao Li, Xiaojie Xu, Kaining Ying, Tong He, Jiangmiao Pang, Yu Qiao, and Kaipeng Zhang. Yume-1.5: A text-controlled interactive world generation model.arXiv preprint arXiv:2512.22096, 2025
-
[20]
Advancing Open-source World Models
Robbyant Team, Zelin Gao, Qiuyu Wang, Yanhong Zeng, Jiapeng Zhu, Ka Leong Cheng, Yixuan Li, Hanlin Wang, Yinghao Xu, Shuailei Ma, et al. Advancing open-source world models.arXiv preprint arXiv:2601.20540, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
2024
-
[22]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Lulu Gu, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, et al. Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
WorldMark: A Unified Benchmark Suite for Interactive Video World Models
Xiaojie Xu, Zhengyuan Lin, Kang He, Yukang Feng, Xiaofeng Mao, Yuanyang Yin, Kaipeng Zhang, and Yongtao Ge. Worldmark: A unified benchmark suite for interactive video world models.arXiv preprint arXiv:2604.21686, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Yixuan Ye, Xuanyu Lu, Yuxin Jiang, Yuchao Gu, Rui Zhao, Qiwei Liang, Jiachun Pan, Fengda Zhang, Weijia Wu, and Alex Jinpeng Wang. Mind: Benchmarking memory consistency and action control in world models.arXiv preprint arXiv:2602.08025, 2026
-
[25]
Meiqi Wu, Zhixin Cai, Fufangchen Zhao, Xiaokun Feng, Rujing Dang, Bingze Song, Ruitian Tian, Jiashu Zhu, Jiachen Lei, Hao Dou, et al. Omni-worldbench: Towards a comprehensive interaction-centric evaluation for world models.arXiv preprint arXiv:2603.22212, 2026
-
[26]
WorldLens: Full-Spectrum Evaluations of Driving World Models in Real World
Ao Liang, Lingdong Kong, Tianyi Yan, Hongsi Liu, Wesley Yang, Ziqi Huang, Wei Yin, Jialong Zuo, Yixuan Hu, Dekai Zhu, et al. Worldlens: Full-spectrum evaluations of driving world models in real world.arXiv preprint arXiv:2512.10958, 2025. 12 WBENCH: A Benchmark for Interactive Video World Model EvaluationPREPRINT
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Video diffusion models
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models. Advances in neural information processing systems, 35:8633–8646, 2022
2022
-
[28]
Align your latents: High-resolution video synthesis with latent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22563–22575, 2023
2023
-
[29]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Sora 2.https://openai.com/zh-Hans-CN/index/sora-2/, 2025
OpenAI. Sora 2.https://openai.com/zh-Hans-CN/index/sora-2/, 2025
2025
-
[31]
Kling 3.0 pro.https://klingai.com, 2025
Kuaishou Technology. Kling 3.0 pro.https://klingai.com, 2025
2025
-
[32]
Veo 3: State-of-the-art video generation with audio
Google DeepMind. Veo 3: State-of-the-art video generation with audio. https://deepmind.google/models/veo/, 2025
2025
-
[33]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Seedance 2.0: Advancing Video Generation for World Complexity
Team Seedance, De Chen, Liyang Chen, Xin Chen, Ying Chen, Zhuo Chen, Zhuowei Chen, Feng Cheng, Tianheng Cheng, Yufeng Cheng, et al. Seedance 2.0: Advancing video generation for world complexity.arXiv preprint arXiv:2604.14148, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Vidu q3 pro.https://www.vidu.com, 2025
Shengshu Technology. Vidu q3 pro.https://www.vidu.com, 2025
2025
-
[36]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Cosmos world foundation models for physical ai
Jinwei Gu. Cosmos world foundation models for physical ai. InProceedings of the 3rd International Workshop on Rich Media With Generative AI, pages 39–39, 2025
2025
-
[38]
Longcat-video technical report.arXiv preprint arXiv:2510.22200, 2025
Meituan LongCat Team, Xunliang Cai, Qilong Huang, Zhuoliang Kang, Hongyu Li, Shijun Liang, Liya Ma, Siyu Ren, Xiaoming Wei, Rixu Xie, et al. Longcat-video technical report.arXiv preprint arXiv:2510.22200, 2025
-
[39]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[40]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[41]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[42]
A path towards autonomous machine intelligence version 0.9
Yann LeCun et al. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27.Open Review, 62(1):1–62, 2022
2022
-
[43]
Happy Oyster: An open-ended world model for real-time world creation and interaction
Alibaba Token Hub. Happy Oyster: An open-ended world model for real-time world creation and interaction. https: //happyoyster.cn/, 2026
2026
-
[44]
Marble: A multimodal world model.https://www.worldlabs.ai/blog/marble-world-model, 2025
World Labs. Marble: A multimodal world model.https://www.worldlabs.ai/blog/marble-world-model, 2025
2025
-
[45]
Vbench++: Comprehensive and versatile benchmark suite for video generative models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, et al. Vbench++: Comprehensive and versatile benchmark suite for video generative models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[46]
Evalcrafter: Benchmarking and evaluating large video generation models
Yaofang Liu, Xiaodong Cun, Xuebo Liu, Xintao Wang, Yong Zhang, Haoxin Chen, Yang Liu, Tieyong Zeng, Raymond Chan, and Ying Shan. Evalcrafter: Benchmarking and evaluating large video generation models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22139–22149, 2024
2024
-
[47]
VideoPhy: Evaluating Physical Commonsense for Video Generation
Hritik Bansal, Zongyu Lin, Tianyi Xie, Zeshun Zong, Michal Yarom, Yonatan Bitton, Chenfanfu Jiang, Yizhou Sun, Kai-Wei Chang, and Aditya Grover. Videophy: Evaluating physical commonsense for video generation.arXiv preprint arXiv:2406.03520, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Towards World Simulator: Crafting Physical Commonsense-Based Benchmark for Video Generation
Fanqing Meng, Jiaqi Liao, Xinyu Tan, Wenqi Shao, Quanfeng Lu, Kaipeng Zhang, Yu Cheng, Dianqi Li, Yu Qiao, and Ping Luo. Towards world simulator: Crafting physical commonsense-based benchmark for video generation.arXiv preprint arXiv:2410.05363, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Worldscore: A unified evaluation benchmark for world generation
Haoyi Duan, Hong-Xing Yu, Sirui Chen, Li Fei-Fei, and Jiajun Wu. Worldscore: A unified evaluation benchmark for world generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 27713–27724, 2025
2025
-
[50]
Dacheng Li, Yunhao Fang, Yukang Chen, Shuo Yang, Shiyi Cao, Justin Wong, Michael Luo, Xiaolong Wang, Hongxu Yin, Joseph E Gonzalez, et al. Worldmodelbench: Judging video generation models as world models.arXiv preprint arXiv:2502.20694, 2025
-
[51]
Yu Shang, Zhuohang Li, Yiding Ma, Weikang Su, Xin Jin, Ziyou Wang, Lei Jin, Xin Zhang, Yinzhou Tang, Haisheng Su, et al. Worldarena: A unified benchmark for evaluating perception and functional utility of embodied world models.arXiv preprint arXiv:2602.08971, 2026
-
[52]
Video-bench: Human-aligned video generation benchmark
Hui Han, Siyuan Li, Jiaqi Chen, Yiwen Yuan, Yuling Wu, Yufan Deng, Chak Tou Leong, Hanwen Du, Junchen Fu, Youhua Li, et al. Video-bench: Human-aligned video generation benchmark. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18858–18868, 2025. 13 WBENCH: A Benchmark for Interactive Video World Model EvaluationPREPRINT
2025
-
[53]
Fetv: A benchmark for fine-grained evaluation of open-domain text-to-video generation.Advances in Neural Information Processing Systems, 36: 62352–62387, 2023
Yuanxin Liu, Lei Li, Shuhuai Ren, Rundong Gao, Shicheng Li, Sishuo Chen, Xu Sun, and Lu Hou. Fetv: A benchmark for fine-grained evaluation of open-domain text-to-video generation.Advances in Neural Information Processing Systems, 36: 62352–62387, 2023
2023
-
[54]
"PhyWorldBench": A Comprehensive Evaluation of Physical Realism in Text-to-Video Models
Jing Gu, Xian Liu, Yu Zeng, Ashwin Nagarajan, Fangrui Zhu, Daniel Hong, Yue Fan, Qianqi Yan, Kaiwen Zhou, Ming-Yu Liu, and Xin Eric Wang. "phyworldbench": A comprehensive evaluation of physical realism in text-to-video models, 2026. URL https://arxiv.org/abs/2507.13428
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
Mmgr: Multi-modal generative reasoning.arXiv preprint arXiv:2512.14691, 2025
Zefan Cai, Haoyi Qiu, Tianyi Ma, Haozhe Zhao, Gengze Zhou, Kung-Hsiang Huang, Parisa Kordjamshidi, Minjia Zhang, Wen Xiao, Jiuxiang Gu, et al. Mmgr: Multi-modal generative reasoning.arXiv preprint arXiv:2512.14691, 2025
-
[56]
Rishi Upadhyay, Howard Zhang, Jim Solomon, Ayush Agrawal, Pranay Boreddy, Shruti Satya Narayana, Yunhao Ba, Alex Wong, Celso M de Melo, and Achuta Kadambi. Worldbench: Disambiguating physics for diagnostic evaluation of world models.arXiv preprint arXiv:2601.21282, 2026
-
[57]
Yiting Lu, Wei Luo, Peiyan Tu, Haoran Li, Hanxin Zhu, Zihao Yu, Xingrui Wang, Xinyi Chen, Xinge Peng, Xin Li, et al. 4dworldbench: A comprehensive evaluation framework for 3d/4d world generation models.arXiv preprint arXiv:2511.19836, 2025
-
[58]
World reasoning arena, 2026
PAN Team, Qiyue Gao, Kun Zhou, Jiannan Xiang, Zihan Liu, Dequan Yang, Junrong Chen, Arif Ahmad, Cong Zeng, Ganesh Bannur, Xinqi Huang, Zheqi Liu, Yi Gu, Yichi Yang, Guangyi Liu, Zhiting Hu, Zhengzhong Liu, and Eric Xing. World reasoning arena, 2026
2026
-
[59]
Yiran Qin, Zhelun Shi, Jiwen Yu, Xijun Wang, Enshen Zhou, Lijun Li, Zhenfei Yin, Xihui Liu, Lu Sheng, Jing Shao, et al. Worldsimbench: Towards video generation models as world simulators.arXiv preprint arXiv:2410.18072, 2024
-
[60]
Hu Yue, Siyuan Huang, Yue Liao, Shengcong Chen, Pengfei Zhou, Liliang Chen, Maoqing Yao, and Guanghui Ren. Ewmbench: Evaluating scene, motion, and semantic quality in embodied world models.arXiv preprint arXiv:2505.09694, 2025
-
[61]
World-in-world: World models in a closed-loop world.arXiv preprint arXiv:2510.18135, 2025
Jiahan Zhang, Muqing Jiang, Nanru Dai, Taiming Lu, Arda Uzunoglu, Shunchi Zhang, Yana Wei, Jiahao Wang, Vishal M Patel, Paul Pu Liang, et al. World-in-world: World models in a closed-loop world.arXiv preprint arXiv:2510.18135, 2025
-
[62]
Yang Zhou, Hao Shao, Letian Wang, Zhuofan Zong, Hongsheng Li, and Steven L Waslander. Drivinggen: A comprehensive benchmark for generative video world models in autonomous driving.arXiv preprint arXiv:2601.01528, 2026
-
[63]
Nano banana 2.https://blog.google/innovation-and-ai/technology/ai/nano-banana-2/, 2025
Google. Nano banana 2.https://blog.google/innovation-and-ai/technology/ai/nano-banana-2/, 2025
2025
-
[64]
GPT-Image-1.5.https://openai.com/zh-Hans-CN/index/new-chatgpt-images-is-here/, 2025
OpenAI. GPT-Image-1.5.https://openai.com/zh-Hans-CN/index/new-chatgpt-images-is-here/, 2025
2025
-
[65]
arXiv preprint arXiv:2508.03789 (2025) 4, 5, 10
Yuhang Ma, Xiaoshi Wu, Keqiang Sun, and Hongsheng Li. Hpsv3: Towards wide-spectrum human preference score, 2025. URLhttps://arxiv.org/abs/2508.03789
-
[66]
Megasam: Accurate, fast and robust structure and motion from casual dynamic videos
Zhengqi Li, Richard Tucker, Forrester Cole, Qianqian Wang, Linyi Jin, Vickie Ye, Angjoo Kanazawa, Aleksander Holynski, and Noah Snavely. Megasam: Accurate, fast and robust structure and motion from casual dynamic videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10486–10496, 2025
2025
-
[67]
DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data
Stephanie Fu, Netanel Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola. Dreamsim: Learning new dimensions of human visual similarity using synthetic data.arXiv preprint arXiv:2306.09344, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[68]
Transnet v2: An effective deep network architecture for fast shot transition detection
Tomás Soucek and Jakub Lokoc. Transnet v2: An effective deep network architecture for fast shot transition detection. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 11218–11221, 2024
2024
-
[69]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
Zhaochong An, Orest Kupyn, Théo Uscidda, Andrea Colaco, Karan Ahuja, Serge Belongie, Mar Gonzalez-Franco, and Marta Tintore Gazulla. Vggrpo: Towards world-consistent video generation with 4d latent reward.arXiv preprint arXiv:2603.26599, 2026
-
[72]
VideoGPA: Distilling Geometry Priors for 3D-Consistent Video Generation
Hongyang Du, Junjie Ye, Xiaoyan Cong, Runhao Li, Jingcheng Ni, Aman Agarwal, Zeqi Zhou, Zekun Li, Randall Balestriero, and Yue Wang. Videogpa: Distilling geometry priors for 3d-consistent video generation.arXiv preprint arXiv:2601.23286, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[73]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[74]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Team Seedance, Heyi Chen, Siyan Chen, Xin Chen, Yanfei Chen, Ying Chen, Zhuo Chen, Feng Cheng, Tianheng Cheng, Xinqi Cheng, et al. Seedance 1.5 pro: A native audio-visual joint generation foundation model.arXiv preprint arXiv:2512.13507, 2025. 14 WBENCH: A Benchmark for Interactive Video World Model EvaluationPREPRINT
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
Hritik Bansal, Clark Peng, Yonatan Bitton, Roman Goldenberg, Aditya Grover, and Kai-Wei Chang. Videophy-2: A challenging action-centric physical commonsense evaluation in video generation.arXiv preprint arXiv:2503.06800, 2025
-
[77]
Kairos 3.0-4b: Real-time generative world model for embodied intelligence
ACE Robotics. Kairos 3.0-4b: Real-time generative world model for embodied intelligence. https://github.com/ kairos-agi/kairos-sensenova/tree/main, 2026
2026
-
[78]
Yixiang Dai, Fan Jiang, Chiyu Wang, Mu Xu, and Yonggang Qi. Fantasyworld: Geometry-consistent world modeling via unified video and 3d prediction.arXiv preprint arXiv:2509.21657, 2025
-
[79]
INSPATIO-WORLD: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling
InSpatio Team, Donghui Shen, Guofeng Zhang, Haomin Liu, Haoyu Ji, Hujun Bao, Hongjia Zhai, Jialin Liu, Jing Guo, Nan Wang, et al. Inspatio-world: A real-time 4d world simulator via spatiotemporal autoregressive modeling.arXiv preprint arXiv:2604.07209, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[80]
Yixuan Zhu, Jiaqi Feng, Wenzhao Zheng, Yuan Gao, Xin Tao, Pengfei Wan, Jie Zhou, and Jiwen Lu. Astra: General interactive world model with autoregressive denoising.arXiv preprint arXiv:2512.08931, 2025
-
[81]
Ruiqi Wu, Xuanhua He, Meng Cheng, Tianyu Yang, Yong Zhang, Zhuoliang Kang, Xunliang Cai, Xiaoming Wei, Chunle Guo, Chongyi Li, et al. Infinite-world: Scaling interactive world models to 1000-frame horizons via pose-free hierarchical memory. arXiv preprint arXiv:2602.02393, 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.