WorldAct: Activating Monolithic 3D Worlds into Interactive-Ready Object-Centric Scenes
Pith reviewed 2026-05-20 19:54 UTC · model grok-4.3
The pith
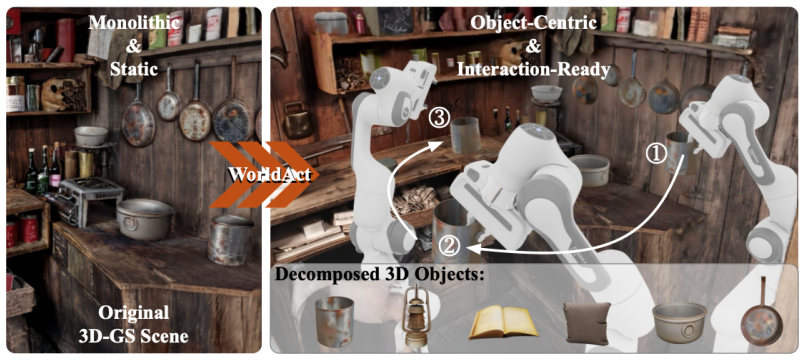
WorldAct converts static generated 3D worlds into editable object-centric scenes that support manipulation and embodied tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
WorldAct is a framework that converts static generated 3D worlds into editable and interaction-ready scenes. It uses a multimodal agent to guide scene decomposition, identify actionable objects, reconstruct geometrically aligned object-level meshes for interaction, and restore the residual background via 3D inpainting. The resulting scenes support object-level editing, collision-aware manipulation, and embodied task execution while preserving global scene coherence.
What carries the argument
Multimodal agent that decomposes scenes, identifies actionable objects, reconstructs geometrically aligned meshes, and applies 3D inpainting to restore backgrounds.
Load-bearing premise
The multimodal agent can accurately identify actionable objects and produce geometrically aligned object-level meshes without compromising overall scene coherence or introducing reconstruction artifacts.
What would settle it
If the activated scenes exhibit visible reconstruction artifacts, loss of global coherence, or inability to perform collision-aware object manipulations without errors, the central claim would be falsified.
Figures







read the original abstract
Recent 3D world modeling systems based on generative scene synthesis, such as Marble, can create coherent and explorable 3D environments, yet their outputs are typically static monolithic assets with limited editability and physical interaction. This restricts their use in immersive content creation and embodied simulation, where generated worlds must be actively modified and manipulated. To tackle this challenge, we present WorldAct, a framework that converts static generated 3D worlds into editable and interaction-ready scenes. WorldAct uses a multimodal agent to guide scene decomposition, identify actionable objects, reconstruct geometrically aligned object-level meshes for interaction, and restore the residual background via 3D inpainting. The resulting scenes support object-level editing, collision-aware manipulation, and embodied task execution while preserving global scene coherence. Experiments show that WorldAct enables richer interaction scenarios than the original generated scenes, suggesting a practical path toward editable and interactive 3D world models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces WorldAct, a framework to convert static monolithic 3D scenes from generative systems (e.g., Marble) into editable, interaction-ready object-centric scenes. It employs a multimodal agent to decompose the scene, identify actionable objects, reconstruct geometrically aligned object-level meshes, and perform 3D inpainting on the residual background. The resulting scenes are claimed to support object-level editing, collision-aware manipulation, and embodied task execution while preserving global scene coherence. Experiments are described as demonstrating richer interaction scenarios than the original generated scenes.
Significance. If the technical claims hold, the work could meaningfully extend generative 3D scene synthesis toward practical use in immersive content creation and embodied AI by adding editability and physical interaction. The pipeline addresses a recognized limitation of monolithic outputs, but the absence of quantitative metrics, baselines, or error analysis in the evaluation makes it difficult to gauge the magnitude of improvement or robustness relative to prior decomposition and inpainting techniques.
major comments (2)
- [Experiments] Experiments section: The central claim that WorldAct enables richer interaction scenarios while preserving global scene coherence is unsupported by any reported quantitative metrics, baselines, ablation studies, or error analysis (e.g., no measures of geometric alignment error, inpainting artifacts, or interaction success rates). This absence directly undermines assessment of whether the multimodal-agent-driven decomposition and reconstruction steps deliver the asserted benefits.
- [Method] Method section on multimodal agent and object reconstruction: The preservation of global scene coherence relies on the assumption that the multimodal agent accurately identifies actionable objects and produces geometrically aligned meshes without boundary errors or artifacts; any such misalignment would propagate through the 3D inpainting of the residual background and compromise subsequent editing and manipulation claims. No validation, quantitative alignment metrics, or failure-case analysis of this step is provided.
minor comments (2)
- [Abstract] Abstract: Consider adding one sentence on the specific multimodal model or agent architecture and any public code release to improve reproducibility.
- [Throughout] Notation: Ensure consistent use of terms such as 'monolithic scene' versus 'object-centric scene' across sections to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of WorldAct to address limitations in generative 3D scene synthesis. We address each major comment below and commit to revisions that strengthen the evaluation and validation of the proposed framework.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The central claim that WorldAct enables richer interaction scenarios while preserving global scene coherence is unsupported by any reported quantitative metrics, baselines, ablation studies, or error analysis (e.g., no measures of geometric alignment error, inpainting artifacts, or interaction success rates). This absence directly undermines assessment of whether the multimodal-agent-driven decomposition and reconstruction steps deliver the asserted benefits.
Authors: We agree that the current experiments section relies primarily on qualitative demonstrations of richer interactions and scene coherence. While visual results illustrate successful object-level editing, collision-aware manipulation, and embodied tasks in the decomposed scenes versus monolithic inputs, we acknowledge the value of quantitative support. In the revised manuscript, we will expand the experiments to include quantitative metrics such as Chamfer distance for geometric alignment of reconstructed meshes, perceptual metrics (e.g., LPIPS) for inpainting quality on rendered views, and task success rates in simulated embodied environments. We will also add baselines comparing against alternative decomposition techniques and ablation studies on the agent's components. These changes will directly substantiate the central claims. revision: yes
-
Referee: [Method] Method section on multimodal agent and object reconstruction: The preservation of global scene coherence relies on the assumption that the multimodal agent accurately identifies actionable objects and produces geometrically aligned meshes without boundary errors or artifacts; any such misalignment would propagate through the 3D inpainting of the residual background and compromise subsequent editing and manipulation claims. No validation, quantitative alignment metrics, or failure-case analysis of this step is provided.
Authors: We agree that explicit validation of the multimodal agent's accuracy is necessary to support claims of preserved global coherence. The method relies on the agent for object identification and aligned mesh reconstruction, with inpainting applied to the residual to maintain consistency. To address this, the revised manuscript will include a new validation subsection reporting quantitative alignment metrics (e.g., boundary IoU and surface-to-surface error for meshes) and a failure-case analysis with examples of agent performance, including cases of boundary misalignment and how the inpainting step mitigates propagation of errors. This will provide concrete evidence for the robustness of the pipeline. revision: yes
Circularity Check
No circularity: engineering pipeline with no derivations or self-referential predictions
full rationale
The paper describes a practical framework for converting static 3D scenes into interactive ones via a multimodal agent for decomposition, object identification, mesh reconstruction, and inpainting. No equations, fitted parameters, predictions from first principles, or self-citation chains appear in the provided abstract or description. The contribution is presented as an applied pipeline whose claims rest on experimental outcomes rather than any reduction of outputs to inputs by construction. This matches the default expectation for non-circular engineering work in computer vision.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Sam 3: Segment anything with concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts. InICLR, 2026
work page 2026
-
[3]
Jiazhong Cen, Jiemin Fang, Chen Yang, Lingxi Xie, Xiaopeng Zhang, Wei Shen, and Qi Tian. Segment any 3d gaussians. InAAAI, 2025
work page 2025
-
[4]
Segment anything in 3d with nerfs
Jiazhong Cen, Zanwei Zhou, Jiemin Fang, Chen Yang, Wei Shen, Lingxi Xie, Dongsheng Jiang, Xiaopeng Zhang, and Qi Tian. Segment anything in 3d with nerfs. InNeurIPS, 2023
work page 2023
-
[5]
Remove: A reference-free metric for object erasure
Aditya Chandrasekar, Goirik Chakrabarty, Jai Bardhan, Ramya Hebbalaguppe, and Prathosh AP. Remove: A reference-free metric for object erasure. InCVPR, 2024
work page 2024
-
[6]
Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation
Rui Chen, Yongwei Chen, Ningxin Jiao, and Kui Jia. Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. InICCV, 2023
work page 2023
-
[7]
SAM 3D: 3Dfy Anything in Images
Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, et al. Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Gaussianeditor: Swift and controllable 3d editing with gaussian splatting
Yiwen Chen, Zilong Chen, Chi Zhang, Feng Wang, Xiaofeng Yang, Yikai Wang, Zhongang Cai, Lei Yang, Huaping Liu, and Guosheng Lin. Gaussianeditor: Swift and controllable 3d editing with gaussian splatting. InCVPR, 2024
work page 2024
-
[9]
Yiwen Chen, Zhihao Li, Yikai Wang, Hu Zhang, Qin Li, Chi Zhang, and Guosheng Lin. Ultra3d: Efficient and high-fidelity 3d generation with part attention.arXiv preprint arXiv:2507.17745, 2025
-
[10]
3dtopia-xl: Scaling high-quality 3d asset generation via primitive diffusion
Zhaoxi Chen, Jiaxiang Tang, Yuhao Dong, Ziang Cao, Fangzhou Hong, Yushi Lan, Tengfei Wang, Haozhe Xie, Tong Wu, Shunsuke Saito, et al. 3dtopia-xl: Scaling high-quality 3d asset generation via primitive diffusion. InCVPR, 2025
work page 2025
-
[11]
Jisheng Chu, Wenrui Li, Rui Zhao, Wangmeng Zuo, Shifeng Chen, and Xiaopeng Fan. Roam- scene3d: Immersive text-to-3d scene generation via adaptive object-aware roaming.arXiv preprint arXiv:2601.19433, 2026
-
[12]
Lucid- dreamer: Domain-free generation of 3d gaussian splatting scenes.TVCG, 2025
Jaeyoung Chung, Suyoung Lee, Hyeongjin Nam, Jaerin Lee, and Kyoung Mu Lee. Lucid- dreamer: Domain-free generation of 3d gaussian splatting scenes.TVCG, 2025
work page 2025
-
[13]
Automated creation of digital cousins for robust policy learning
Tianyuan Dai, Josiah Wong, Yunfan Jiang, Chen Wang, Cem Gokmen, Ruohan Zhang, Jiajun Wu, and Li Fei-Fei. Automated creation of digital cousins for robust policy learning. InCoRL, 2024
work page 2024
-
[14]
Hiscene: creating hierarchical 3d scenes with isometric view generation
Wenqi Dong, Bangbang Yang, Zesong Yang, Yuan Li, Tao Hu, Hujun Bao, Yuewen Ma, and Zhaopeng Cui. Hiscene: creating hierarchical 3d scenes with isometric view generation. In ACMMM, 2025
work page 2025
-
[15]
Antoine Guédon and Vincent Lepetit. Sugar: Surface-aligned gaussian splatting for efficient 3d mesh reconstruction and high-quality mesh rendering. InCVPR, 2024
work page 2024
-
[16]
Text2room: Extracting textured 3d meshes from 2d text-to-image models
Lukas Höllein, Ang Cao, Andrew Owens, Justin Johnson, and Matthias Nießner. Text2room: Extracting textured 3d meshes from 2d text-to-image models. InICCV, 2023
work page 2023
-
[17]
3d gaussian inpainting with depth-guided cross-view consistency
Sheng-Yu Huang, Zi-Ting Chou, and Yu-Chiang Frank Wang. 3d gaussian inpainting with depth-guided cross-view consistency. InCVPR, 2025
work page 2025
-
[18]
Midi: Multi-instance diffusion for single image to 3d scene generation
Zehuan Huang, Yuan-Chen Guo, Xingqiao An, Yunhan Yang, Yangguang Li, Zi-Xin Zou, Ding Liang, Xihui Liu, Yan-Pei Cao, and Lu Sheng. Midi: Multi-instance diffusion for single image to 3d scene generation. InCVPR, 2025. 10
work page 2025
-
[19]
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Team Hunyuan3D, Shuhui Yang, Mingxin Yang, Yifei Feng, Xin Huang, Sheng Zhang, Zebin He, Di Luo, Haolin Liu, Yunfei Zhao, et al. Hunyuan3d 2.1: From images to high-fidelity 3d assets with production-ready pbr material.arXiv preprint arXiv:2506.15442, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
HY-World 2.0: A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds
Team HY-World, Chenjie Cao, Xuhui Zuo, Zhenwei Wang, Yisu Zhang, Junta Wu, Zhenyang Liu, Yuning Gong, Yang Liu, Bo Yuan, et al. Hy-world 2.0: A multi-modal world model for reconstructing, generating, and simulating 3d worlds.arXiv preprint arXiv:2604.14268, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Poisson surface reconstruction
Michael Kazhdan, Matthew Bolitho, and Hugues Hoppe. Poisson surface reconstruction. In SGP, 2006
work page 2006
-
[22]
3d gaussian splatting for real-time radiance field rendering.NeurIPS, 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.NeurIPS, 2023
work page 2023
-
[23]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. In ICCV, 2023
work page 2023
-
[24]
Hunyuan3D 2.5: Towards High-Fidelity 3D Assets Generation with Ultimate Details
Zeqiang Lai, Yunfei Zhao, Haolin Liu, Zibo Zhao, Qingxiang Lin, Huiwen Shi, Xianghui Yang, Mingxin Yang, Shuhui Yang, Yifei Feng, et al. Hunyuan3d 2.5: Towards high-fidelity 3d assets generation with ultimate details.arXiv preprint arXiv:2506.16504, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Instant3d: Fast text-to-3d with sparse-view generation and large reconstruction model
Jiahao Li, Hao Tan, Kai Zhang, Zexiang Xu, Fujun Luan, Yinghao Xu, Yicong Hong, Kalyan Sunkavalli, Greg Shakhnarovich, and Sai Bi. Instant3d: Fast text-to-3d with sparse-view generation and large reconstruction model.arXiv preprint arXiv:2311.06214, 2023
-
[26]
Weiyu Li, Xuanyang Zhang, Zheng Sun, Di Qi, Hao Li, Wei Cheng, Weiwei Cai, Shihao Wu, Jiarui Liu, Zihao Wang, et al. Step1x-3d: Towards high-fidelity and controllable generation of textured 3d assets.arXiv preprint arXiv:2505.07747, 2025
-
[27]
Diffueraser: A diffusion model for video inpainting.arXiv preprint arXiv:2501.10018, 2025
Xiaowen Li, Haolan Xue, Peiran Ren, and Liefeng Bo. Diffueraser: A diffusion model for video inpainting.arXiv preprint arXiv:2501.10018, 2025
-
[28]
Zhihao Li, Yufei Wang, Heliang Zheng, Yihao Luo, and Bihan Wen. Sparc3d: Sparse representa- tion and construction for high-resolution 3d shapes modeling.arXiv preprint arXiv:2505.14521, 2025
-
[29]
Magic3d: High-resolution text-to-3d content creation
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High-resolution text-to-3d content creation. InCVPR, 2023
work page 2023
-
[30]
Yuchen Lin, Chenguo Lin, Panwang Pan, Honglei Yan, Yiqiang Feng, Yadong Mu, and Katerina Fragkiadaki. Partcrafter: Structured 3d mesh generation via compositional latent diffusion transformers.arXiv preprint arXiv:2506.05573, 2025
-
[31]
Scenethesis: Combining language and visual priors for 3d scene generation
Lu Ling, Chen-Hsuan Lin, Tsung-Yi Lin, Yifan Ding, Yu Zeng, Yichen Sheng, Yunhao Ge, Ming-Yu Liu, Aniket Bera, and Zhaoshuo Li. Scenethesis: Combining language and visual priors for 3d scene generation. InICLR, 2026
work page 2026
-
[32]
Syncdreamer: Generating multiview-consistent images from a single-view image
Yuan Liu, Cheng Lin, Zijiao Zeng, Xiaoxiao Long, Lingjie Liu, Taku Komura, and Wenping Wang. Syncdreamer: Generating multiview-consistent images from a single-view image. In ICLR, 2024
work page 2024
-
[33]
Depthlab: From partial to complete.arXiv preprint arXiv:2412.18153, 2024
Zhiheng Liu, Ka Leong Cheng, Qiuyu Wang, Shuzhe Wang, Hao Ouyang, Bin Tan, Kai Zhu, Yujun Shen, Qifeng Chen, and Ping Luo. Depthlab: From partial to complete.arXiv preprint arXiv:2412.18153, 2024
-
[34]
Zhiheng Liu, Hao Ouyang, Qiuyu Wang, Ka Leong Cheng, Jie Xiao, Kai Zhu, Nan Xue, Yu Liu, Yujun Shen, and Yang Cao. Infusion: Inpainting 3d gaussians via learning depth completion from diffusion prior.arXiv preprint arXiv:2404.11613, 2024
-
[35]
Wonder3d: Single image to 3d using cross-domain diffusion
Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, et al. Wonder3d: Single image to 3d using cross-domain diffusion. InCVPR, 2024. 11
work page 2024
-
[36]
Gaga: Group any gaussians via 3d-aware memory bank.TMLR, 2026
Weijie Lyu, Xueting Li, Abhijit Kundu, Yi-Hsuan Tsai, and Ming-Hsuan Yang. Gaga: Group any gaussians via 3d-aware memory bank.TMLR, 2026
work page 2026
-
[37]
Realfusion: 360deg reconstruction of any object from a single image
Luke Melas-Kyriazi, Iro Laina, Christian Rupprecht, and Andrea Vedaldi. Realfusion: 360deg reconstruction of any object from a single image. InCVPR, 2023
work page 2023
-
[38]
Scenegen: Single-image 3d scene generation in one feedforward pass
Yanxu Meng, Haoning Wu, Ya Zhang, and Weidi Xie. Scenegen: Single-image 3d scene generation in one feedforward pass. In3DV, 2026
work page 2026
-
[39]
Nerf: Representing scenes as neural radiance fields for view synthesis.CACM, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.CACM, 2021
work page 2021
-
[40]
Spin-nerf: Multiview segmentation and perceptual inpainting with neural radiance fields
Ashkan Mirzaei, Tristan Aumentado-Armstrong, Konstantinos G Derpanis, Jonathan Kelly, Mar- cus A Brubaker, Igor Gilitschenski, and Alex Levinshtein. Spin-nerf: Multiview segmentation and perceptual inpainting with neural radiance fields. InCVPR, 2023
work page 2023
-
[41]
Point-E: A System for Generating 3D Point Clouds from Complex Prompts
Alex Nichol, Heewoo Jun, Prafulla Dhariwal, Pamela Mishkin, and Mark Chen. Point-e: A system for generating 3d point clouds from complex prompts.arXiv preprint arXiv:2212.08751, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [42]
-
[43]
Dinov2: Learning robust visual features without supervision.TMLR, 2025
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.TMLR, 2025
work page 2025
-
[44]
Dreamfusion: Text-to-3d using 2d diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. InICLR, 2023
work page 2023
-
[45]
Langsplat: 3d language gaussian splatting
Minghan Qin, Wanhua Li, Jiawei Zhou, Haoqian Wang, and Hanspeter Pfister. Langsplat: 3d language gaussian splatting. InCVPR, 2024
work page 2024
-
[46]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InICML, 2021
work page 2021
-
[47]
Xcube: Large-scale 3d generative modeling using sparse voxel hierarchies
Xuanchi Ren, Jiahui Huang, Xiaohui Zeng, Ken Museth, Sanja Fidler, and Francis Williams. Xcube: Large-scale 3d generative modeling using sparse voxel hierarchies. InCVPR, 2024
work page 2024
-
[48]
Tobias Sautter, Jan-Niklas Dihlmann, and Hendrik Lensch. 3d-re-gen: 3d reconstruction of indoor scenes with a generative framework.arXiv preprint arXiv:2512.17459, 2025
-
[49]
A recipe for generating 3d worlds from a single image
Katja Schwarz, Denis Rozumny, Samuel Rota Bulò, Lorenzo Porzi, and Peter Kontschieder. A recipe for generating 3d worlds from a single image. InICCV, 2025
work page 2025
-
[50]
Yukai Shi, Weiyu Li, Zihao Wang, Hongyang Li, Xingyu Chen, Ping Tan, and Lei Zhang. Scenemaker: Open-set 3d scene generation with decoupled de-occlusion and pose estimation model.arXiv preprint arXiv:2512.10957, 2025
-
[51]
Realmdreamer: Text- driven 3d scene generation with inpainting and depth diffusion
Jaidev Shriram, Alex Trevithick, Lingjie Liu, and Ravi Ramamoorthi. Realmdreamer: Text- driven 3d scene generation with inpainting and depth diffusion. In3DV, 2025
work page 2025
-
[52]
Dreamcraft3d: Hierarchical 3d generation with bootstrapped diffusion prior
Jingxiang Sun, Bo Zhang, Ruizhi Shao, Lizhen Wang, Wen Liu, Zhenda Xie, and Yebin Liu. Dreamcraft3d: Hierarchical 3d generation with bootstrapped diffusion prior. InICLR, 2024
work page 2024
-
[53]
Dreamgaussian: Generative gaussian splatting for efficient 3d content creation
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. Dreamgaussian: Generative gaussian splatting for efficient 3d content creation. InICLR, 2024
work page 2024
-
[54]
Make-it-3d: High-fidelity 3d creation from a single image with diffusion prior
Junshu Tang, Tengfei Wang, Bo Zhang, Ting Zhang, Ran Yi, Lizhuang Ma, and Dong Chen. Make-it-3d: High-fidelity 3d creation from a single image with diffusion prior. InICCV, 2023
work page 2023
-
[55]
Lion: Latent point diffusion models for 3d shape generation.NeurIPS, 2022
Arash Vahdat, Francis Williams, Zan Gojcic, Or Litany, Sanja Fidler, Karsten Kreis, et al. Lion: Latent point diffusion models for 3d shape generation.NeurIPS, 2022. 12
work page 2022
-
[56]
Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation
Haochen Wang, Xiaodan Du, Jiahao Li, Raymond A Yeh, and Greg Shakhnarovich. Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. InCVPR, 2023
work page 2023
-
[57]
Gaussianeditor: Editing 3d gaussians delicately with text instructions
Junjie Wang, Jiemin Fang, Xiaopeng Zhang, Lingxi Xie, and Qi Tian. Gaussianeditor: Editing 3d gaussians delicately with text instructions. InCVPR, 2024
work page 2024
-
[58]
Inpaint360gs: Efficient object-aware 3d inpainting via gaussian splatting for 360deg scenes
Shaoxiang Wang, Shihong Zhang, Christen Millerdurai, Rüdiger Westermann, Didier Stricker, and Alain Pagani. Inpaint360gs: Efficient object-aware 3d inpainting via gaussian splatting for 360deg scenes. InWACV, 2026
work page 2026
-
[59]
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Pro- lificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. InNeurIPS, 2023
work page 2023
-
[60]
Ziqian Wang, Yonghao He, Licheng Yang, Wei Zou, Hongxuan Ma, Liu Liu, Wei Sui, Yuxin Guo, and Hu Su. Tabletopgen: Instance-level interactive 3d tabletop scene generation from text or single image.arXiv preprint arXiv:2512.01204, 2025
-
[61]
World Labs. Marble. https://www.worldlabs.ai/blog/marble-world-model, 2025. Accessed: 2026-03-07
work page 2025
-
[62]
arXiv preprint arXiv:2509.25079 , year=
Guanjun Wu, Jiemin Fang, Chen Yang, Sikuang Li, Taoran Yi, Jia Lu, Zanwei Zhou, Jiazhong Cen, Lingxi Xie, Xiaopeng Zhang, et al. Unilat3d: Geometry-appearance unified latents for single-stage 3d generation.arXiv preprint arXiv:2509.25079, 2025
-
[63]
Direct3d: Scalable image-to-3d generation via 3d latent diffusion transformer
Shuang Wu, Youtian Lin, Feihu Zhang, Yifei Zeng, Jingxi Xu, Philip Torr, Xun Cao, and Yao Yao. Direct3d: Scalable image-to-3d generation via 3d latent diffusion transformer. InNeurIPS, 2024
work page 2024
-
[64]
Shuang Wu, Youtian Lin, Feihu Zhang, Yifei Zeng, Yikang Yang, Yajie Bao, Jiachen Qian, Siyu Zhu, Xun Cao, Philip Torr, et al. Direct3d-s2: Gigascale 3d generation made easy with spatial sparse attention.arXiv preprint arXiv:2505.17412, 2025
-
[65]
Sage: Scalable agentic 3d scene generation for embodied ai
Hongchi Xia, Xuan Li, Zhaoshuo Li, Qianli Ma, Jiashu Xu, Ming-Yu Liu, Yin Cui, Tsung-Yi Lin, Wei-Chiu Ma, Shenlong Wang, Shuran Song, and Fangyin Wei. Sage: Scalable agentic 3d scene generation for embodied ai. InCVPR, 2026
work page 2026
-
[66]
Octfusion: Octree-based diffusion models for 3d shape generation.Computer Graphics F orum, 2025
Bojun Xiong, Si-Tong Wei, Xin-Yang Zheng, Yan-Pei Cao, Zhouhui Lian, and Peng-Shuai Wang. Octfusion: Octree-based diffusion models for 3d shape generation.Computer Graphics F orum, 2025
work page 2025
-
[67]
Neurallift- 360: Lifting an in-the-wild 2d photo to a 3d object with 360deg views
Dejia Xu, Yifan Jiang, Peihao Wang, Zhiwen Fan, Yi Wang, and Zhangyang Wang. Neurallift- 360: Lifting an in-the-wild 2d photo to a 3d object with 360deg views. InCVPR, 2023
work page 2023
-
[68]
Jiale Xu, Weihao Cheng, Yiming Gao, Xintao Wang, Shenghua Gao, and Ying Shan. In- stantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruc- tion models.arXiv preprint arXiv:2404.07191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[69]
Atlas gaussians diffusion for 3d generation
Haitao Yang, Yuan Dong, Hanwen Jiang, Dejia Xu, Georgios Pavlakos, and Qixing Huang. Atlas gaussians diffusion for 3d generation. InICLR, 2025
work page 2025
-
[70]
Maniqa: Multi-dimension attention network for no-reference image quality assessment
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. InCVPR, 2022
work page 2022
-
[71]
Sceneweaver: All-in-one 3d scene synthesis with an extensible and self-reflective agent
Yandan Yang, Baoxiong Jia, Shujie Zhang, and Siyuan Huang. Sceneweaver: All-in-one 3d scene synthesis with an extensible and self-reflective agent. InNeurIPS, 2025
work page 2025
-
[72]
Cast: Component-aligned 3d scene reconstruction from an rgb image.TOG, 2025
Kaixin Yao, Longwen Zhang, Xinhao Yan, Yan Zeng, Qixuan Zhang, Lan Xu, Wei Yang, Jiayuan Gu, and Jingyi Yu. Cast: Component-aligned 3d scene reconstruction from an rgb image.TOG, 2025
work page 2025
-
[73]
Chongjie Ye, Yushuang Wu, Ziteng Lu, Jiahao Chang, Xiaoyang Guo, Jiaqing Zhou, Hao Zhao, and Xiaoguang Han. Hi3dgen: High-fidelity 3d geometry generation from images via normal bridging.arXiv preprint arXiv:2503.22236, 2025. 13
-
[74]
Gaussian grouping: Segment and edit anything in 3d scenes
Mingqiao Ye, Martin Danelljan, Fisher Yu, and Lei Ke. Gaussian grouping: Segment and edit anything in 3d scenes. InECCV, 2024
work page 2024
-
[75]
Gaussiandreamer: Fast generation from text to 3d gaussians by bridging 2d and 3d diffusion models
Taoran Yi, Jiemin Fang, Junjie Wang, Guanjun Wu, Lingxi Xie, Xiaopeng Zhang, Wenyu Liu, Qi Tian, and Xinggang Wang. Gaussiandreamer: Fast generation from text to 3d gaussians by bridging 2d and 3d diffusion models. InCVPR, 2024
work page 2024
-
[76]
Omniseg3d: Omniversal 3d segmentation via hierarchical contrastive learning
Haiyang Ying, Yixuan Yin, Jinzhi Zhang, Fan Wang, Tao Yu, Ruqi Huang, and Lu Fang. Omniseg3d: Omniversal 3d segmentation via hierarchical contrastive learning. InCVPR, 2024
work page 2024
-
[77]
Wonder- world: Interactive 3d scene generation from a single image
Hong-Xing Yu, Haoyi Duan, Charles Herrmann, William T Freeman, and Jiajun Wu. Wonder- world: Interactive 3d scene generation from a single image. InCVPR, 2025
work page 2025
-
[78]
Biao Zhang, Jiapeng Tang, Matthias Niessner, and Peter Wonka. 3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models.ACM TOG, 2023
work page 2023
-
[79]
Clay: A controllable large-scale generative model for creating high-quality 3d assets.ACM TOG, 2024
Longwen Zhang, Ziyu Wang, Qixuan Zhang, Qiwei Qiu, Anqi Pang, Haoran Jiang, Wei Yang, Lan Xu, and Jingyi Yu. Clay: A controllable large-scale generative model for creating high-quality 3d assets.ACM TOG, 2024
work page 2024
-
[80]
ObjectClear: Complete object removal via object-effect attention,
Jixin Zhao, Shangchen Zhou, Zhouxia Wang, Peiqing Yang, and Chen Change Loy. Objectclear: Complete object removal via object-effect attention.arXiv preprint arXiv:2505.22636, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.