GUI-C²: Coarse-to-Fine GUI Grounding via Difficulty-Aware Reinforcement Learning
Pith reviewed 2026-06-28 22:50 UTC · model grok-4.3
The pith
Difficulty-aware reinforcement learning with coarse-to-fine refinement improves GUI grounding by weighting samples and adaptively narrowing regions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
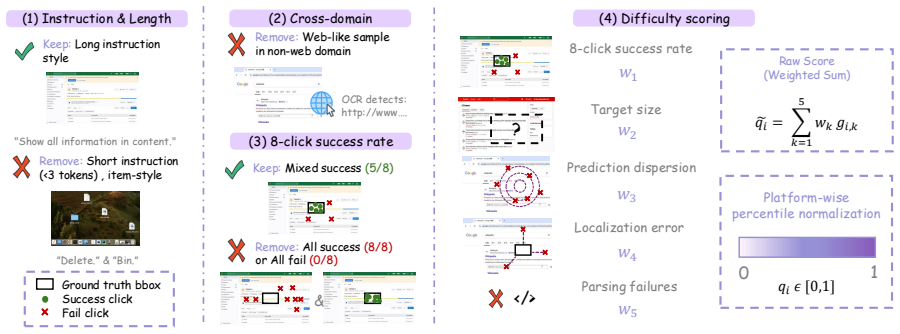
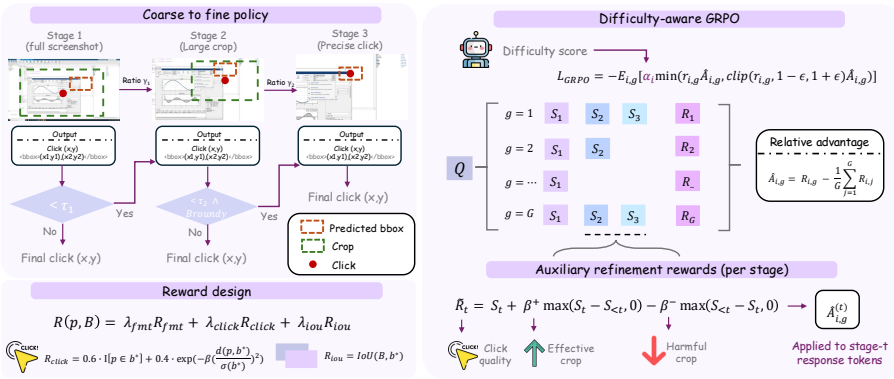
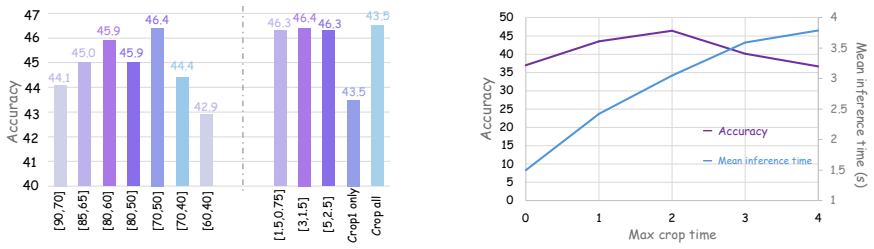
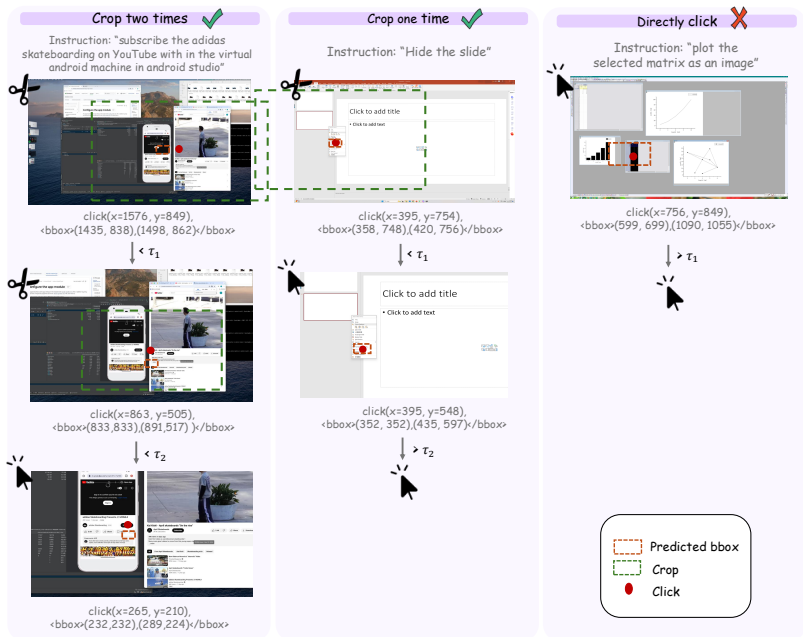
The central claim is that GUI-D identifies training-worthy samples through testing and scores them by difficulty to guide weighted training, while GUI-C² employs an area-gated coarse-to-fine refinement that progressively narrows the visual field via model uncertainty signals and applies improvement-aware stage rewards to ensure each step advances accuracy, together enabling state-of-the-art GUI grounding performance with reduced inference overhead.
What carries the argument
GUI-C²'s area-gated coarse-to-fine refinement mechanism that narrows the visual field via uncertainty signals and applies improvement-aware stage rewards, supported by GUI-D difficulty scoring for sample weighting.
If this is right
- Training focuses compute on high-value samples instead of treating all examples equally.
- Region selection automatically reserves context for large targets while increasing precision for small ones.
- Decision-making stays simple enough for small-parameter models without added inference latency.
- Overall grounding accuracy reaches state-of-the-art levels on interface interaction tasks.
Where Pith is reading between the lines
- The same difficulty scoring and gated refinement pattern could transfer to other agent tasks that involve sequential visual decisions.
- Public release of the scored dataset would allow direct testing of whether difficulty weighting alone lifts other grounding methods.
- If the refinement reliably avoids collapse, similar uncertainty-driven narrowing might reduce context overhead in document or scene understanding agents.
Load-bearing premise
The difficulty scores and improvement-aware rewards will correctly identify valuable samples and ensure each refinement step advances accuracy without introducing new training instabilities or time costs.
What would settle it
Running the method on standard GUI grounding benchmarks and finding no accuracy gain over baselines that treat all samples equally and use fixed region sizes.
Figures

read the original abstract
Existing agentic reinforcement learning methods for GUI grounding have limitations at two levels. At the data level, current approaches typically treat all training samples equally, although their training value to the baseline model varies with difficulty. Overlooking this can greatly reduce training efficiency or even cause collapse. At the strategy level, existing frameworks struggle to balance the trade-off between cropping larger regions for sufficient context and smaller ones for reduced redundancy, a tension inherent to tool-augmented grounding agents. In addition, overly complex decision-making is difficult for small-parameter models and significantly increases inference time. To address these issues, at the data level, we propose GUI-D, a data mining and difficulty scoring pipeline that identifies the training-worthy samples by proper testing and assigns difficulty scores to guide subsequent training weights. At the strategy level, we propose GUI-C$^2$, which employs an area-gated coarse-to-fine refinement mechanism that progressively narrows the visual field via model-internal uncertainty signals, adaptively reserving context for large targets while amplifying precision for small ones, reinforced by improvement-aware stage rewards that ensure each refinement genuinely advances grounding. Meanwhile, we simplify the decision-making process to greatly reduce additional inference time. Finally, extensive experiments show that our method achieves state-of-the-art performance. The code and data will be publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GUI-D, a data mining and difficulty scoring pipeline that identifies training-worthy GUI grounding samples and assigns scores to guide RL training weights, addressing uniform treatment of samples that can reduce efficiency or cause collapse. At the strategy level, it introduces GUI-C², an area-gated coarse-to-fine refinement mechanism that uses model-internal uncertainty signals to progressively narrow the visual field, adaptively balancing context for large targets against precision for small ones, reinforced by improvement-aware stage rewards; decision-making is also simplified to reduce inference time. The central claim is that these components together yield state-of-the-art performance on GUI grounding benchmarks.
Significance. If the empirical gains are shown to arise specifically from the difficulty weighting and uncertainty-gated refinement rather than from hyperparameter tuning or dataset effects, the work could improve training stability and inference efficiency for small-parameter GUI agents; the public release of code and data would further strengthen reproducibility.
major comments (2)
- [Abstract] Abstract: the SOTA claim is presented without any tables, figures, benchmark names, baseline comparisons, or ablation results, so it is impossible to determine whether the reported gains isolate the contribution of GUI-D difficulty scoring or the area-gated refinement from ordinary RL stability improvements.
- [Abstract] Abstract: the description of the improvement-aware stage rewards and uncertainty signals does not specify how the reward is formulated or how the gating threshold is chosen, leaving open whether these mechanisms are load-bearing or could be replicated by simpler curriculum or fixed-crop baselines.
minor comments (1)
- [Abstract] Abstract: the acronym 'GUI-C²' is introduced without expansion or explanation of the superscript notation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, drawing on the full experimental and methodological details presented in the paper body.
read point-by-point responses
-
Referee: [Abstract] Abstract: the SOTA claim is presented without any tables, figures, benchmark names, baseline comparisons, or ablation results, so it is impossible to determine whether the reported gains isolate the contribution of GUI-D difficulty scoring or the area-gated refinement from ordinary RL stability improvements.
Authors: The abstract is a high-level summary of contributions and claims, as is standard. The manuscript's Experiments section provides tables with benchmark names, baseline comparisons, figures, and ablation studies that isolate the contributions of GUI-D difficulty scoring and the area-gated coarse-to-fine refinement. These results demonstrate that performance gains exceed those from standard RL stability improvements alone, with specific controls for hyperparameter and dataset effects. revision: no
-
Referee: [Abstract] Abstract: the description of the improvement-aware stage rewards and uncertainty signals does not specify how the reward is formulated or how the gating threshold is chosen, leaving open whether these mechanisms are load-bearing or could be replicated by simpler curriculum or fixed-crop baselines.
Authors: The abstract summarizes at a high level without mathematical detail. Section 3 of the manuscript formally defines the improvement-aware stage reward formulation (tied to per-stage grounding accuracy gains) and the uncertainty-based gating threshold selection. The same section includes ablations contrasting these components against simpler curriculum learning and fixed-crop baselines, confirming they are load-bearing for the reported stability and efficiency gains. revision: no
Circularity Check
No significant circularity detected
full rationale
The paper describes empirical proposals (GUI-D difficulty pipeline and GUI-C² area-gated refinement with improvement-aware rewards) validated through experiments claiming SOTA results. No equations, first-principles derivations, or predictions are presented that reduce to fitted inputs or self-definitions by construction. Claims rest on experimental outcomes rather than self-referential mechanisms or load-bearing self-citations. This is a standard non-circular empirical ML paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL: " 'urlintro :=
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRINGS urlintro eprinturl eprintpr...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Anthropic. 2024. https://www.anthropic.com/news/developing-computer-use Developing a computer use model
2024
- [4]
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. http://arxiv.org/abs/250...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [6]
- [7]
-
[8]
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Yantao Li, Jianbing Zhang, and Zhiyong Wu. 2024. http://arxiv.org/abs/2401.10935 Seeclick: Harnessing gui grounding for advanced visual gui agents
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, and Yu Su. 2025. http://arxiv.org/abs/2410.05243 Navigating the digital world as humans do: Universal visual grounding for gui agents
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Zhangxuan Gu, Zhengwen Zeng, Zhenyu Xu, Xingran Zhou, Shuheng Shen, Yunfei Liu, Beitong Zhou, Changhua Meng, Tianyu Xia, Weizhi Chen, Yue Wen, Jingya Dou, Fei Tang, Jinzhen Lin, Yulin Liu, Zhenlin Guo, Yichen Gong, Heng Jia, Changlong Gao, Yuan Guo, Yong Deng, Zhenyu Guo, Liang Chen, and Weiqiang Wang. 2025. http://arxiv.org/abs/2508.10833 Ui-venus techni...
-
[11]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. 2025. http://dx.doi.org/10.1038/s41586-025-09422-z Deepseek-r1 incentivizes reasoning in llms through reinforcement learning . Nature, 645(8081):633--638
- [12]
-
[13]
Chao Hao, Zezheng Wang, Yanhua Huang, Ruiwen Xu, Wenzhe Niu, Xin Liu, and Zitong Yu. 2025 b . Dynamic collaboration of multi-language models based on minimal complete semantic units. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 12905--12922
2025
-
[14]
Chao Hao, Jun Xu, Ji Du, Shuo Ye, Ziyue Qiao, Xiaodong Cun, Guangcong Wang, Xubin Zheng, and Zitong Yu. 2026. Seg-agent: Test-time multimodal reasoning for training-free language-guided segmentation. arXiv preprint arXiv:2605.12953
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [15]
- [16]
- [17]
- [18]
-
[19]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual instruction tuning. Advances in neural information processing systems, 36:34892--34916
2023
-
[20]
Yuhang Liu, Pengxiang Li, Congkai Xie, Xavier Hu, Xiaotian Han, Shengyu Zhang, Hongxia Yang, and Fei Wu. 2025. http://arxiv.org/abs/2504.14239 Infigui-r1: Advancing multimodal gui agents from reactive actors to deliberative reasoners
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [21]
-
[22]
Zhengxi Lu, Yuxiang Chai, Yaxuan Guo, Xi Yin, Liang Liu, Hao Wang, Han Xiao, Shuai Ren, Guanjing Xiong, and Hongsheng Li. 2025. http://arxiv.org/abs/2503.21620 Ui-r1: Enhancing efficient action prediction of gui agents by reinforcement learning
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Run Luo, Lu Wang, Wanwei He, Longze Chen, Jiaming Li, and Xiaobo Xia. 2025. http://arxiv.org/abs/2504.10458 Gui-r1 : A generalist r1-style vision-language action model for gui agents
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Wenzhe Niu, Zongxia Xie, Yanru Sun, Chao Hao, Wei He, and Man Xu. 2025. Langtime: A language-guided unified model for time series forecasting with proximal policy optimization. In AI for Time Series, pages 151--172. CRC Press
2025
-
[25]
OpenAI. 2024. http://arxiv.org/abs/2410.21276 Gpt-4o system card
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [26]
-
[27]
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, Wanjun Zhong, Kuanye Li, Jiale Yang, Yu Miao, Woyu Lin, Longxiang Liu, Xu Jiang, Qianli Ma, Jingyu Li, Xiaojun Xiao, Kai Cai, Chuang Li, Yaowei Zheng, Chaolin Jin, Chen Li, Xiao Zhou, Minchao Wang, Haoli Chen, Zhaojian Li, Haihua Ya...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Chris Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, et al. 2025. Androidworld: A dynamic benchmarking environment for autonomous agents. In International Conference on Learning Representations, volume 2025, pages 406--441
2025
-
[29]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. http://arxiv.org/abs/2402.03300 Deepseekmath: Pushing the limits of mathematical reasoning in open language models
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, Ruochen Xu, and Tiancheng Zhao. 2025. http://arxiv.org/abs/2504.07615 Vlm-r1: A stable and generalizable r1-style large vision-language model
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Fei Tang, Bofan Chen, Zhengxi Lu, Tongbo Chen, Songqin Nong, Tao Jiang, Wenhao Xu, Weiming Lu, Jun Xiao, Yueting Zhuang, and Yongliang Shen. 2026. http://arxiv.org/abs/2604.14113 Ui-zoomer: Uncertainty-driven adaptive zoom-in for gui grounding
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [32]
-
[33]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. 2024. http://arxiv.org/abs/2409.12191 Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Charles, Zhilin Yang, and Tao Yu
Xinyuan Wang, Bowen Wang, Dunjie Lu, Junlin Yang, Tianbao Xie, Junli Wang, Jiaqi Deng, Xiaole Guo, Yiheng Xu, Chen Henry Wu, Zhennan Shen, Zhuokai Li, Ryan Li, Xiaochuan Li, Junda Chen, Boyuan Zheng, Peihang Li, Fangyu Lei, Ruisheng Cao, Yeqiao Fu, Dongchan Shin, Martin Shin, Jiarui Hu, Yuyan Wang, Jixuan Chen, Yuxiao Ye, Danyang Zhang, Dikang Du, Hao Hu,...
-
[35]
Yangyue Wang, Harshvardhan Sikka, Yash Mathur, Tony Zhou, Jinu Nyachhyon, and Pranav Guruprasad. 2026. http://arxiv.org/abs/2604.14262 Gui-perturbed: Domain randomization reveals systematic brittleness in gui grounding models
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [36]
-
[37]
Qianhui Wu, Kanzhi Cheng, Rui Yang, Chaoyun Zhang, Jianwei Yang, Huiqiang Jiang, Jian Mu, Baolin Peng, Bo Qiao, Reuben Tan, Si Qin, Lars Liden, Qingwei Lin, Huan Zhang, Tong Zhang, Jianbing Zhang, Dongmei Zhang, and Jianfeng Gao. 2025 b . http://arxiv.org/abs/2506.03143 Gui-actor: Coordinate-free visual grounding for gui agents
-
[38]
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, and Yu Qiao. 2024. http://arxiv.org/abs/2410.23218 Os-atlas: A foundation action model for generalist gui agents
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Tianbao Xie, Jiaqi Deng, Xiaochuan Li, Junlin Yang, Haoyuan Wu, Jixuan Chen, Wenjing Hu, Xinyuan Wang, Yuhui Xu, Zekun Wang, Yiheng Xu, Junli Wang, Doyen Sahoo, Tao Yu, and Caiming Xiong. 2025. http://arxiv.org/abs/2505.13227 Scaling computer-use grounding via user interface decomposition and synthesis
-
[40]
Yiheng Xu, Zekun Wang, Junli Wang, Dunjie Lu, Tianbao Xie, Amrita Saha, Doyen Sahoo, Tao Yu, and Caiming Xiong. 2025. http://arxiv.org/abs/2412.04454 Aguvis: Unified pure vision agents for autonomous gui interaction
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Yan Yang, Dongxu Li, Yutong Dai, Yuhao Yang, Ziyang Luo, Zirui Zhao, Zhiyuan Hu, Junzhe Huang, Amrita Saha, Zeyuan Chen, Ran Xu, Liyuan Pan, Silvio Savarese, Caiming Xiong, and Junnan Li. 2025. http://arxiv.org/abs/2507.05791 Gta1: Gui test-time scaling agent
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Jiabo Ye, Xi Zhang, Haiyang Xu, Haowei Liu, Junyang Wang, Zhaoqing Zhu, Ziwei Zheng, Feiyu Gao, Junjie Cao, Zhengxi Lu, Jitong Liao, Qi Zheng, Fei Huang, Jingren Zhou, and Ming Yan. 2025. http://arxiv.org/abs/2508.15144 Mobile-agent-v3: Fundamental agents for gui automation
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [43]
-
[44]
Borui Zhang, Bo Zhang, Bo Wang, Wenzhao Zheng, Yuhao Cheng, Liang Tang, Yiqiang Yan, Jie Zhou, and Jiwen Lu. 2026. http://arxiv.org/abs/2605.06664 Bami: Training-free bias mitigation in gui grounding
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [45]
- [46]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.